eiConsole v.18R2
Documentation
Validation
Overview
The Validation Processor is a Processor component in the eiConsole that allows users to perform validation against an XML input source using a set of defined Rules and Validators. The output and behavior governing the conditions under which output is altered and produced is also configurable. This tutorial offers a step-by-step walk-through of the Validation Processor for the purposes of performing simple schema (XSD).
The Validation Processor
Because validation is often used as a stand-alone service or in conjunction with existing or planned components, this tutorial will cover using validation in isolation. The first thing the user should therefore do is to create a new Route in the Route File Management dialog:
In this case, we’ll simply name our Route “Validation Tutorial Route“:
To open the Route for editing, double-click on its entry in the Routes table:
The next thing a user needs to do is select a Source or Target to configure the Processor in. For this tutorial, we’ll be using the Source side of a Route to perform the validation. Using the Source is generally preferable because it allows the user to make use of the Forking and Routing stages, which can better serve the overall validation methodology by encapsulating the validation within its own re-usable Route.

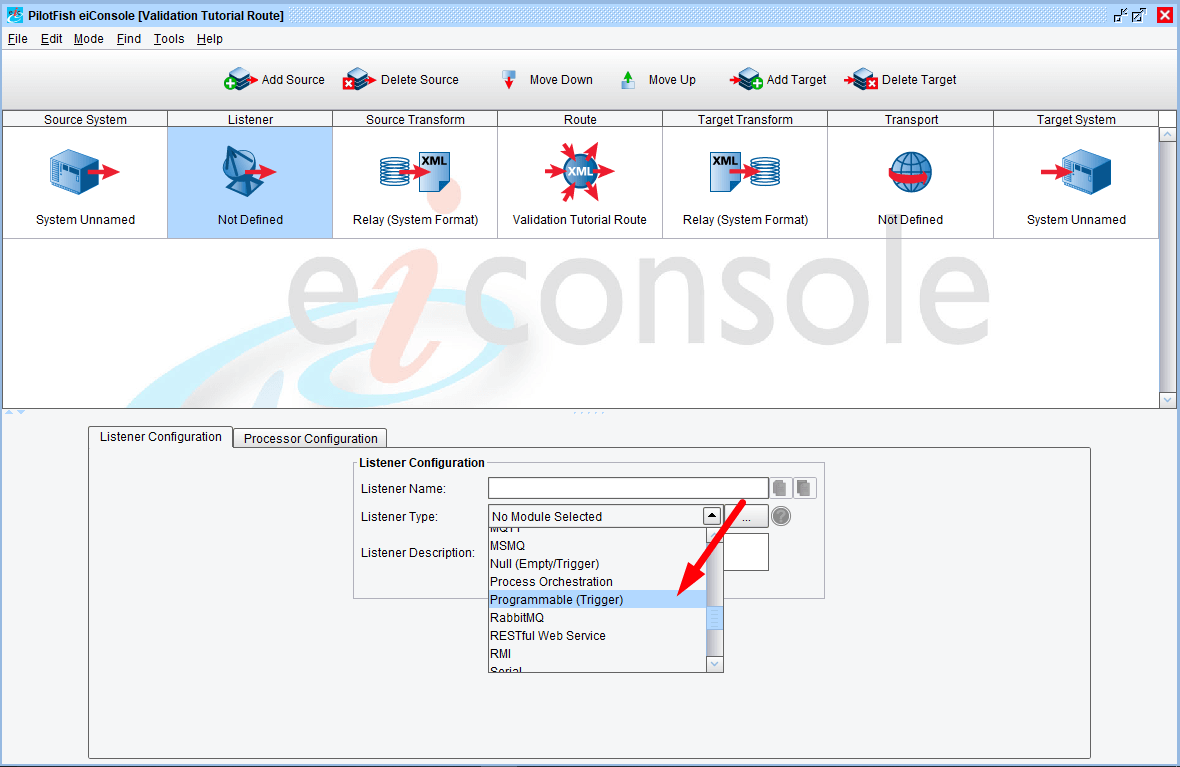
Since we want this Route to be re-usable, we can define our Source Listener as a Programmable (Trigger) type, meaning it will be invoked by other Routes, or as a simple HTTP endpoint using the “HTTP Post” type. For this example, we’ll use the former:
We’ll now select the Processor Configuration tab so that we can add our Validation Processor. Simply click the aforementioned tab and add a new Validation Processor:
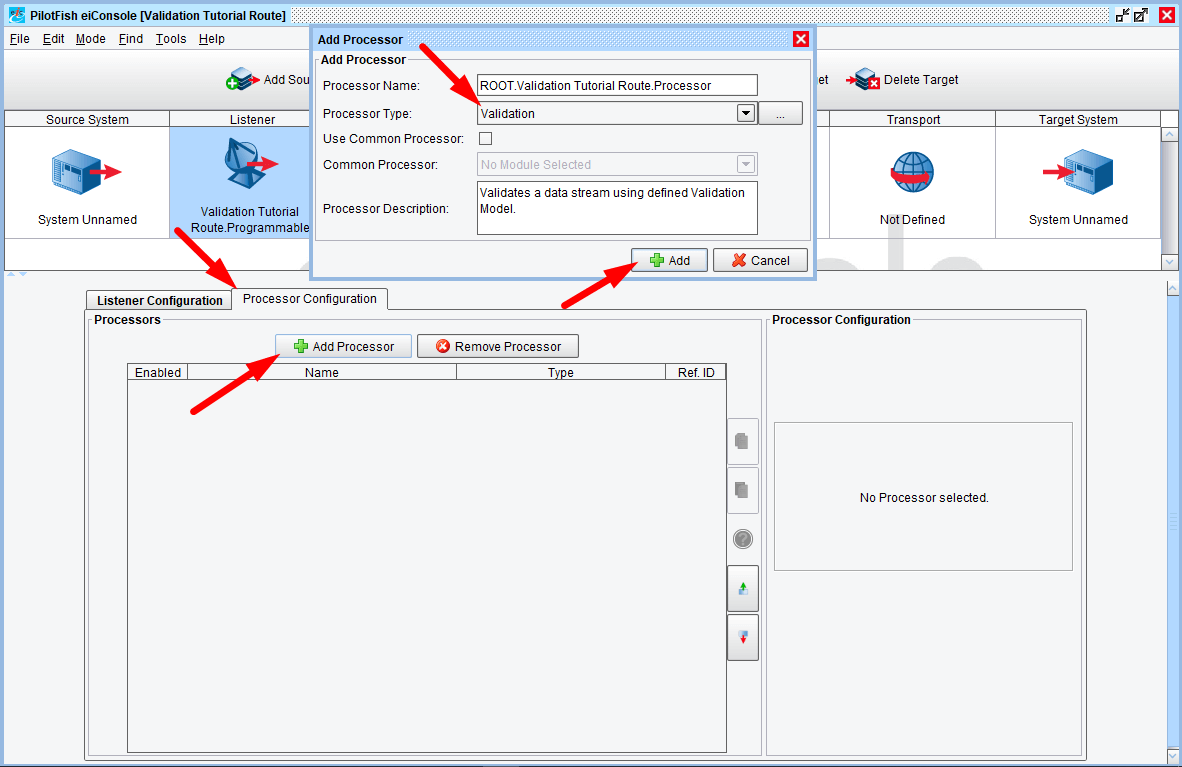
With the Validation Processor added and selected, you will now be presented with a configuration panel for it, shown below:
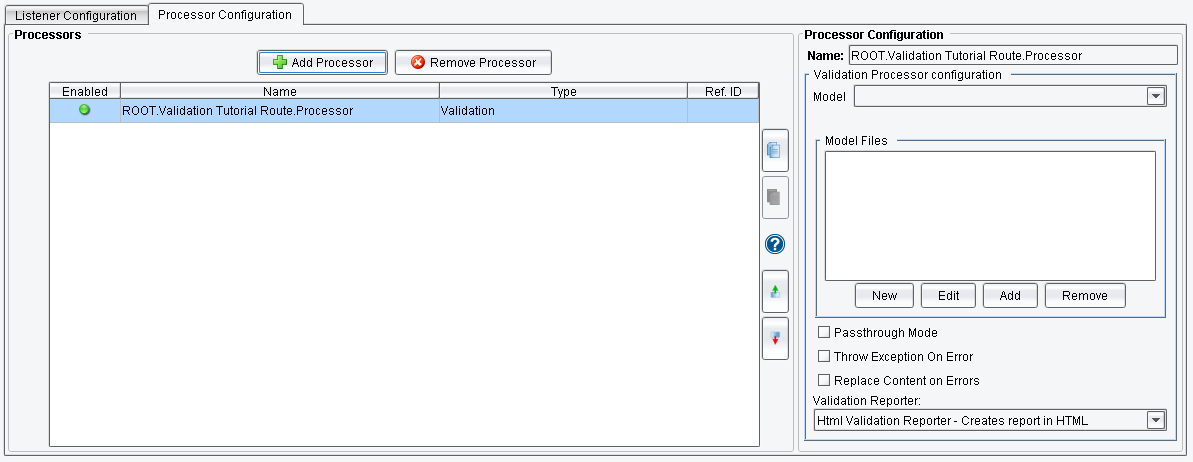
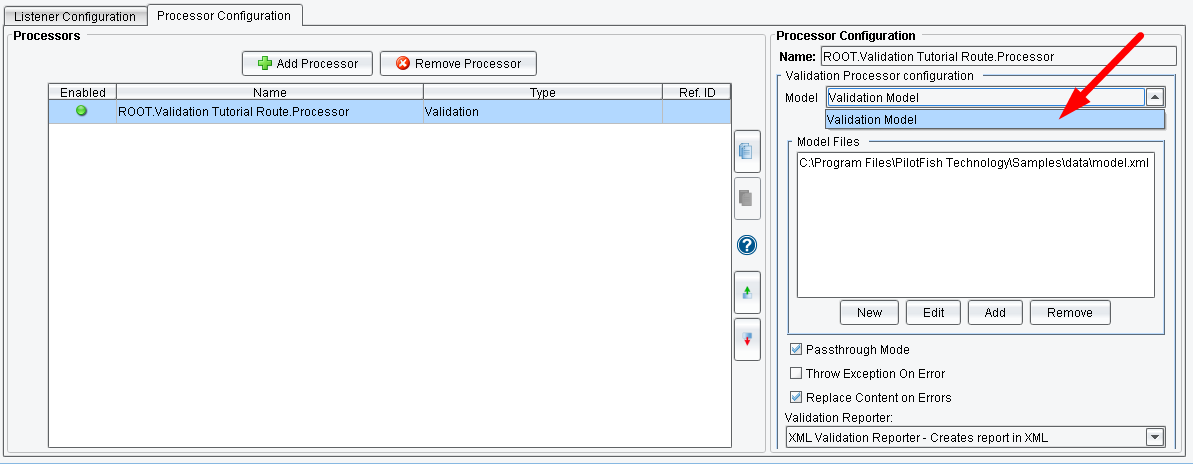
The Validation Processor makes use of “Model Files,” which are XML files describing the various validation rules, validator and other settings that make up what is known collectively as a “Model.” The user may add or modify one or more Model files to the “Model Files” list using the “New”, “Edit”, “Add” and “Remove” buttons. Once some number of Model files are defined, the user selects a single Model from the “Model” drop-down. The selected Model is what gets “executed” against the transaction XML.
There are then four options available to the user which define the behavior of the Processor itself:
Passthrough Mode: If this is enabled, the transaction content is only conditionally replaced with the validation results. If disabled (the default), then the Processor will always replace the transaction content with validation results, regardless of success.
Throw Exception On Error: If this is enabled, any “error” level messages produced by the Validation Model will cause the Processor stage to fail with an Exception. This is treated like any other stage failure within the eiPlatform and can be handled accordingly using Transaction Monitors.
Replace Content On Errors: If this and “Passthrough Mode” are both enabled, then the transaction content is only replaced with validation results if any “error” level messages are present.
Validation Reporter: This determines the (optional) validation result output formatting. By default, the “Html Validation Reporter” is used, which creates an HTML table to display the errors. Most users will want to select the “XML Validation Reporter”, as that allows the results to be transformed and routed on.
The recommended configuration for these options, and the one this tutorial will use, is for “Passthrough Mode” and “Replace Content on Errors” to both be enabled and the “XML Validation Reporter” selected, as shown below:
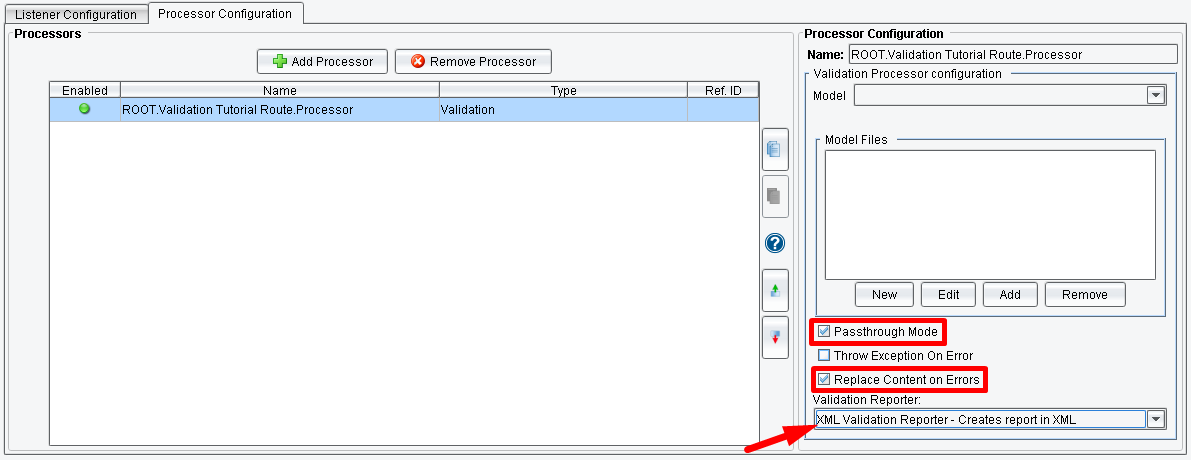
This configuration will cause successful messages to exit the Processor stage unaltered in their original format. If any errors are encountered, the message / transaction content will be replaced with an XML format describing the validation results. We can (and will) then route and transform these results.
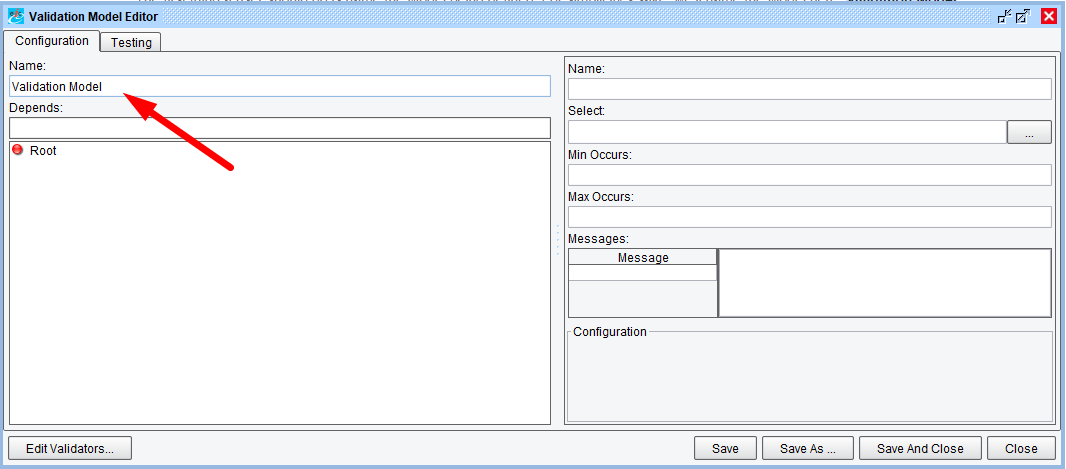
The next step is to define and configure a Validation Model. Since no Model is currently available, the user should click the “New” button to open the Validation Model Editor, shown below:

The Validation Model Editor is organized into “Configuration” and “Testing” modes, which can be switched between by selecting from the appropriate tabs at the top of the dialog. Defined and available Validators can be configured via the “Edit Validators…” button at the bottom of the dialog, while the configuration can be saved or the Editor closed using the buttons at the bottom-right.
The first thing a user should do is name the Model being defined. For simplicity’s sake, we’ll name the Model here “Validation Model”:
Validation is defined primarily in terms of Rules and Groups, which can be altered using the tree structure to the left. A “Root” element is always present. A Rule represents a single Validation rule, composed of a Name, an XPath expression to which it applies, and then any specific customizations of a selected Validator. A Group represents an arbitrary grouping of Rules. To add a new Rule, right-click on the “Root” node in the tree and select “Add Rule” from the pop-up menu:

The user may define any number of Groups and Rules in however complex a hierarchy is desired. Evaluation of these nodes is performed from the top-down. Both Rules and Groups have a “Select” field where the user provides an XPath expression. Any nodes returned from this expression are evaluated against a Rule’s Validator, while Groups pass the resulting Nodes to their own child Groups and Rules. The “Select” field’s expression is always evaluated against the current context node. In this way, nesting of Groups and Rules allows the user to define a validation hierarchy.
The user can now select the added Rule (named “???” in the tree) and provide a Name in the configuration panel on the right. For the initial Rule, we’ll simply name it “Schema Validation Rule”:
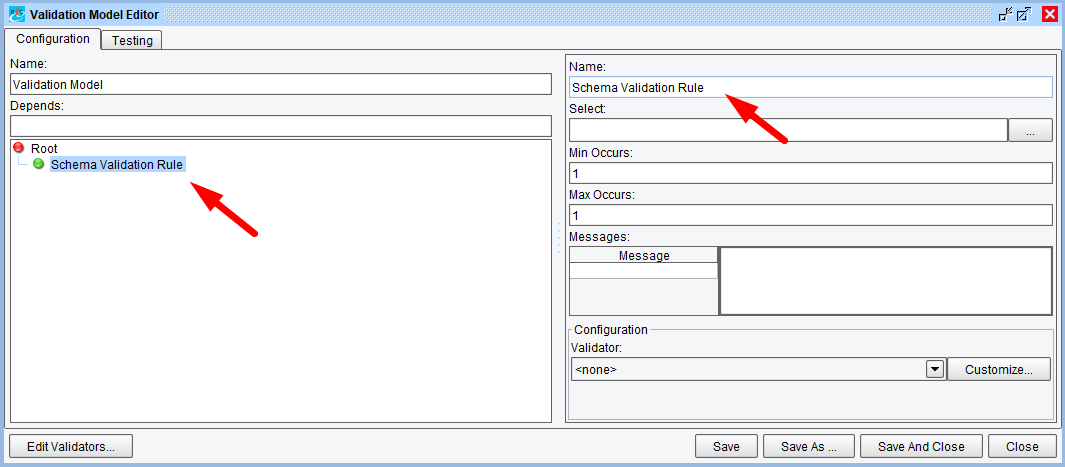
The user will next need to provide an XPath expression for this Rule to apply to. Because this Rule will be used for XSD-based validation, we’ll want to provide our root-level element. We want to retrieve this regardless of namespace, so we can use a somewhat complex XPath expression here to grab the root-level element by name:
/*[local-name(.) = 'People']
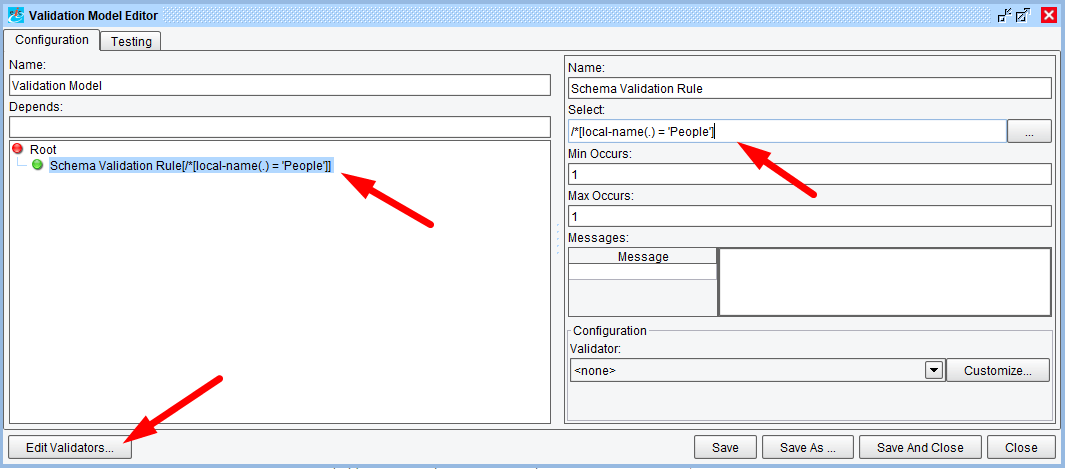
The user may also provide “Min Occurs” and “Max Occurs.” These fields specify how often this Rule must and may apply to a given set of nodes. Unless a Rule is being applied to multiple nodes throughout a source document, these can be left at their default values of “1” and “1.”
The “Messages” table allows the user to specify custom output messages for validation results. Most Validators provide their own message contents and they are not required to utilize user-provided messages. For this reason, it is usually sufficient to leave this table unconfigured, “as-is.”
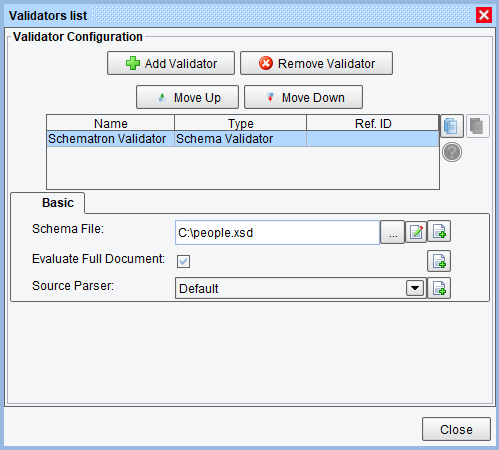
The last field of interest is the “Validator” drop-down which is used to select the Validator, this Rule will apply against its selected nodes. As we have no Validators yet defined, the user should click the “Edit Validators…” button at the bottom-left of the screen. This will raise the Validators List dialog:

This dialog is similar in function to the Processors List dialog in the eiConsole. The user may add, remove and arbitrarily re-order Validators. To add a new Validator, simply click the “Add Validator” button to raise a dialog for selecting from available Validator types. We’ll select the “Schema Validator” for our purposes:
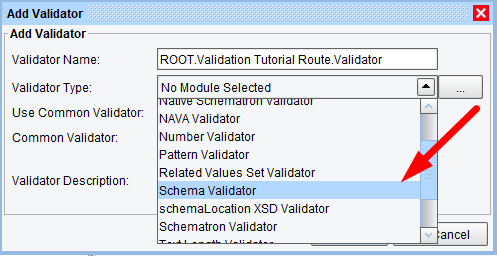
There are a number of Validators available out-of-the-box. Most of these vary between evaluating the given context node against some configuration (such as the “Date Validator,” which ensures that a node’s text content conforms to a date format) or evaluating the node or entire document against a more complex structure (such as the “Schema Validator,” “Generic XSLT Validator,” “Schematron Validator,” etc). The user therefore has the option of defining the validation entirely using the Model Editor and discrete Validators for each node within the Rule tree or passing the document in its entirety to existing artifacts, such as XSLT, XSD, and Schematron files.
With the Schema Validator selected, the user may now configure it by providing a schema location and options regarding what portions of the source document to use as well as the model:
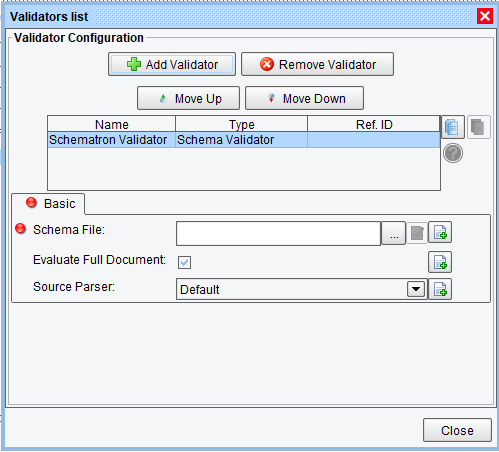
The “Schema File” field expects a file system path to a XSD to be used for schema validation. While this path is relative to the Model’s eventual file representation, the Model file can be placed in any directory and referenced arbitrarily. For this reason, it is generally preferable to provide an absolute location. We’ll point this to “C:\people.xsd,” the source for which should have been provided with this tutorial.
“Evaluate Full Document” specifies if the XSD should be applied to the whole document or just the context node. By default, this is enabled, since most schema files are not well-adapted to contextual evaluation.
“Source Parser” allows the user to pick between SAX and DOM parsers for the handling of the XSD. Unless there is a particular reason for preferring one of these, it’s generally advisable to just leave this up to the system default.
Finally, with our Validator configured, we can close the dialog:
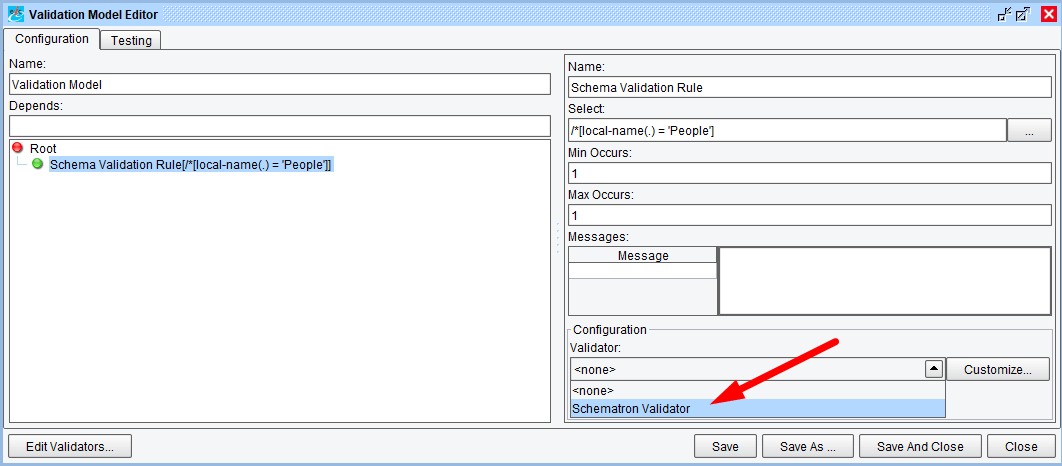
We can now select our configured Validator using the “Validator” field:
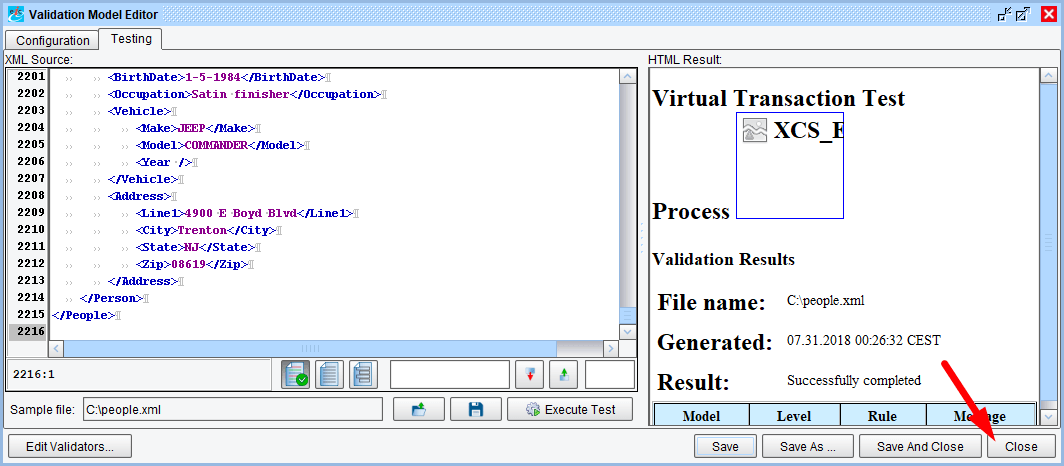
To test the Validation configuration, select the “Testing” tab at the top of the dialog, then load the provided “people.xml” sample:
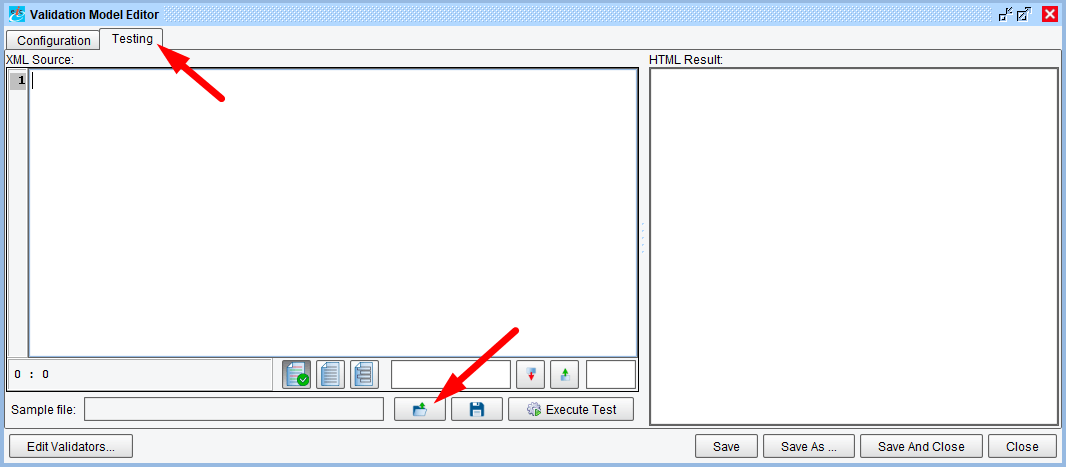
With the sample file loaded, click the “Execute Test” button. The “HTML Result” panel on the right side of the dialog will show simple table results for the validation:

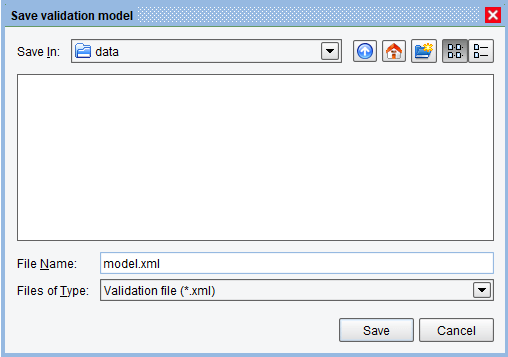
Finally, save the Validation Model by clicking the “Save” button. The Model file can be saved to any location, but the “data” location of the current working directory is usually a good start. Name it model.xml:
Now that the Validation Model is defined and saved, press the “Close” button to return to the eiConsole screen.
Select the newly defined Model for the “Model” drop-down field.
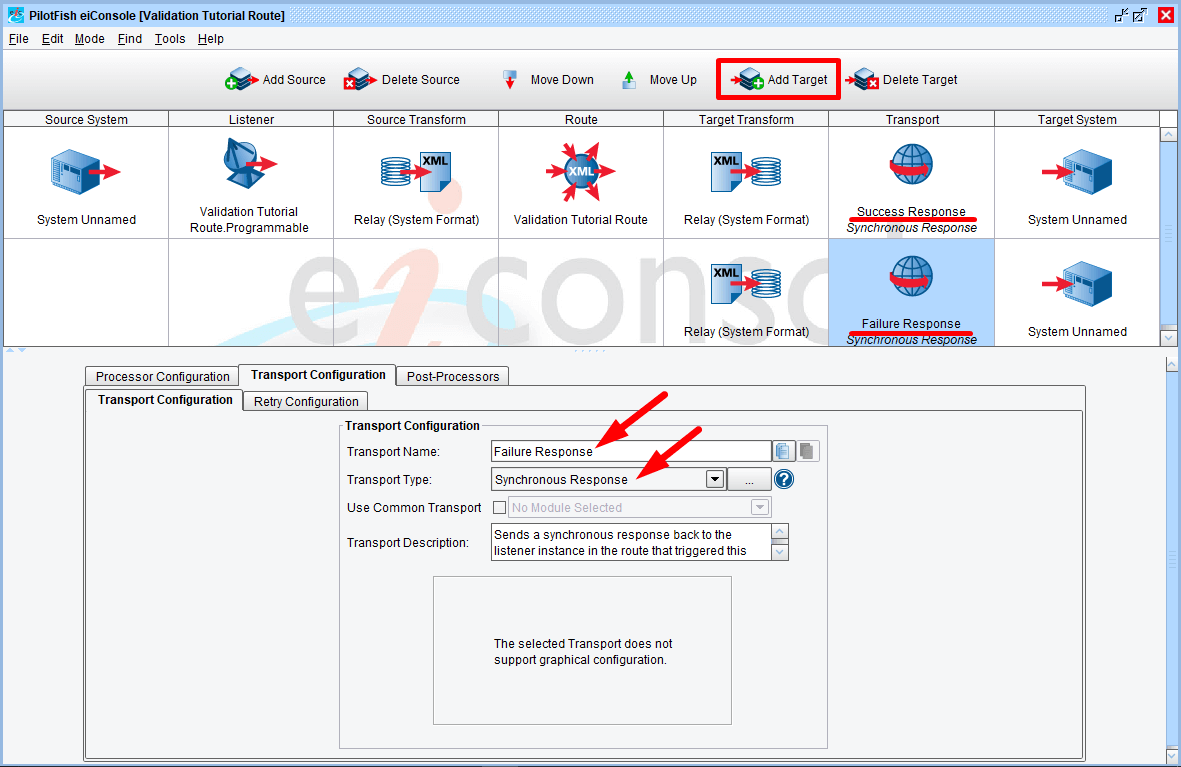
The next step is to configure the rest of the Route to handle the results of our Validation. We’ll start by defining two synchronous Targets: one for successes and another for failures. Both will use “Synchronous Response” transports; the only difference in this case will be their names – Success Response and Failure Response:
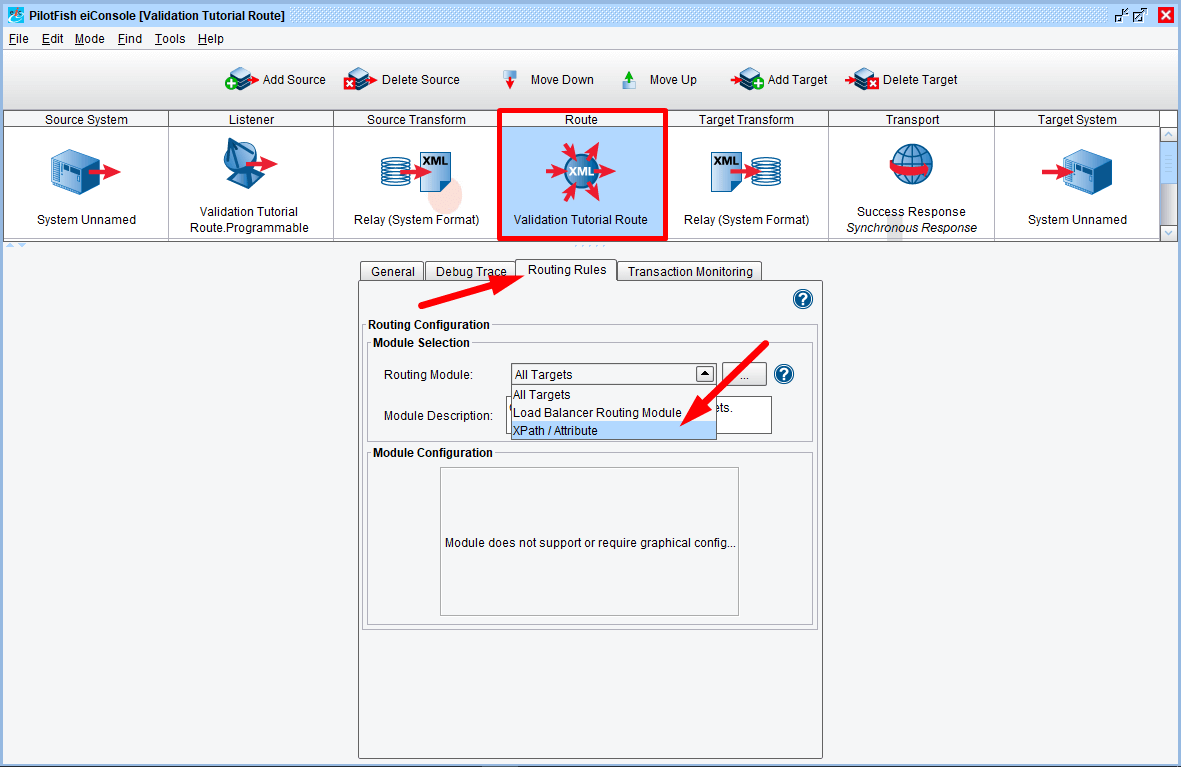
We’ll now configure the Routing stage to conditionally route messages based on the presence of error results. The logic will be fairly straight-forward: if there exists a “Result” node with a “Level” of “Error,” then the transaction will be routed to the “Failure Response” target. Otherwise, it will be routed to the “Success Response” target. The user could then configure transforms, processors and so on for both or either transports (or additional transports) to handle the validation results.
Select the “Route” stage and then the “Routing Rules” tab, then select the “XPath / Attribute” option from the drop-down:
While this tutorial isn’t intended to cover routing, the premise is fairly simple: click on the “Add Rules” button to add a Rule. Each Rule has one type of expression (configured via drop down menu) and one or more Targets associated with it. Our first Rule will use a “XPath Query” as an Expression and “Failure Response” as a Transport.
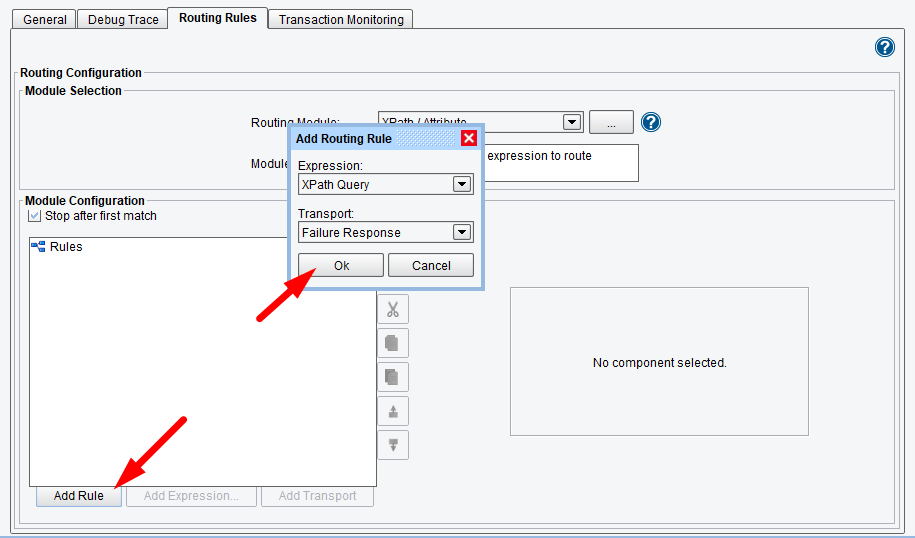
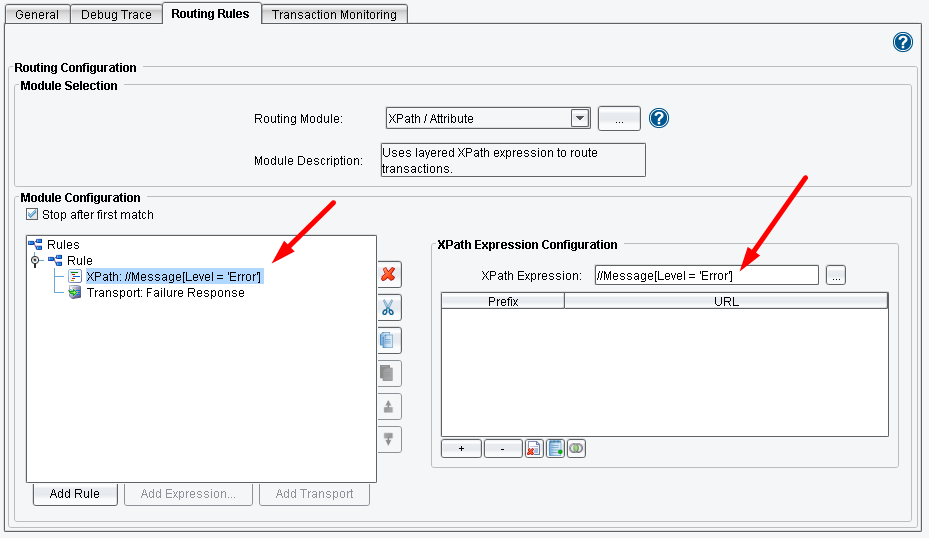
Set the value for the XPath Expression:
//Message[Level = 'Error']
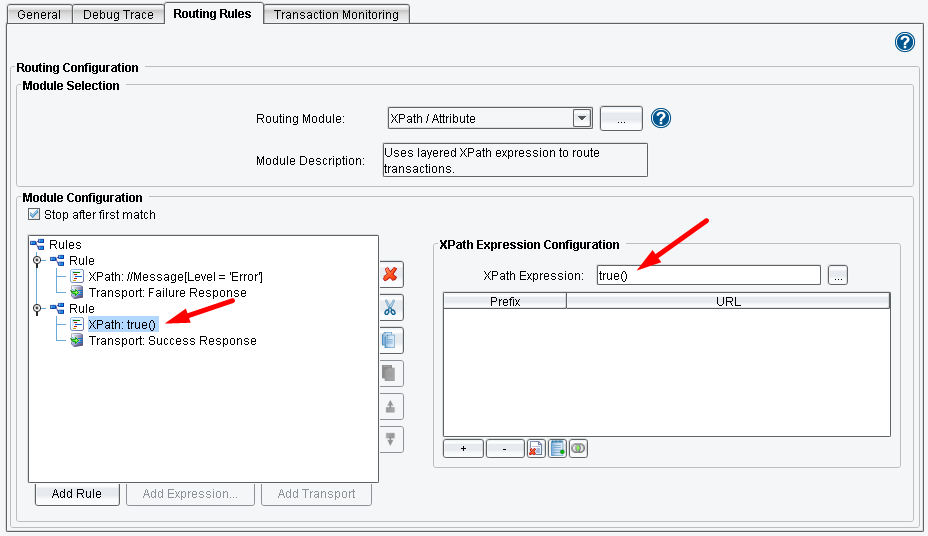
Next, we’ll configure an additional “catch-all” Rule. This one is pretty simple: just use the Xpath “true()” expression:
Finally, you may test the Route using the eiConsole testing mode. Samples for valid and invalid messages should have been provided with this tutorial.