eiConsole for MISMO – Getting Started Tutorial

Welcome to the eiConsole for MISMO Getting Started Tutorial. Before starting this tutorial, users should become familiar with the basic concepts and terminology used in the eiConsole by completing the General Quick Start Tutorial and the General Level I Tutorials (Modules 1-13). The MISMO XML standard provides a set of common messaging constructs to support core data exchange processes in the Mortgage and Lending space, including residential and commercial standards for processes from loan origination, to appraisal, closing, and servicing. MISMO has streamlined workflow, reduced cost, and improved transparency across the industry. However, the implementation of standards across heterogeneous systems and entities does not come without challenges and costs. The eiConsole for MISMO provides an integrated development environment that will facilitate the initial development and ongoing maintenance of MISMO compliant interfaces. In this tutorial, you’ll use the MISMO credit reporting standard to explore the eiConsole’s paint-by-numbers, assembly line approach to developing integration solutions. You’ll develop an interface that accepts applicant data in a delimited file format and translates it into a MISMO compliant Credit Request. Let’s get started.
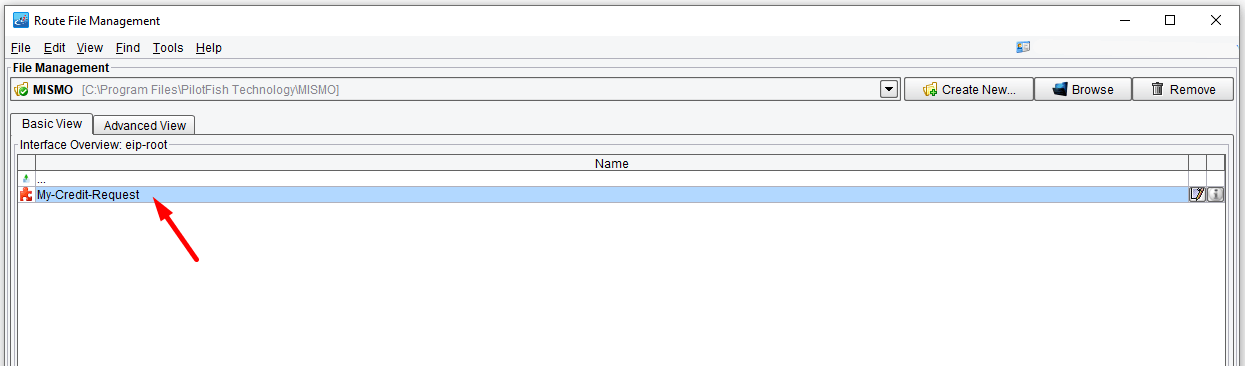
When you first open the eiConsole you’ll see the Route File Management screen. The first thing you’ll want to do to create a new interface. Click the Add Route button.

When prompted to provide a name for the route enter My-Credit-Request and click OK.

A new row will appear in the Route Overview grid. To open this for work, select the row and click Edit Route.
This will bring you to the main eiConsole screen. Here you’ll need to define the flow of data between the Source System and Target System. The Source System will be producing a Credit Request, the Target System will be consuming it.
Your job now is to work your way from left to right across each stage. You’ll begin with the Source System that will somehow produce data to be consumed by a Listener. Once the Listener accepts the data you’ll perform a Source Transformation, first into XML and then into the MISMO format. Next, there’s a Routing stage where you can configure Routing Rules and Transaction Monitoring (exception handling). Then, you have the opportunity to apply a Target Transformation. Finally, there’s a Transport that takes the formatted data and passes it along to the consuming system. The Target System then consumes the data. This can happen either in a real-time synchronous fashion, or asynchronous or batch.

Begin by clicking the Listener icon. The first thing you need to configure is how the data will be accepted by the interface. You do this by determining the type of connectivity that’s most appropriate for the Source System you’re connecting to. In this tutorial, you’ll be assuming that the file is dropped in a directory on the local file system. From the Listener type drop-down, select the Directory / File Listener. Note that the eiConsole supports a number of different types of connectivity mechanisms. Some of these mechanisms are proactive, meaning they go out to look for the data. In other cases, the data will be pushed to the Listener. Examples here would be a Web Form posting data in, or a Web Service call.
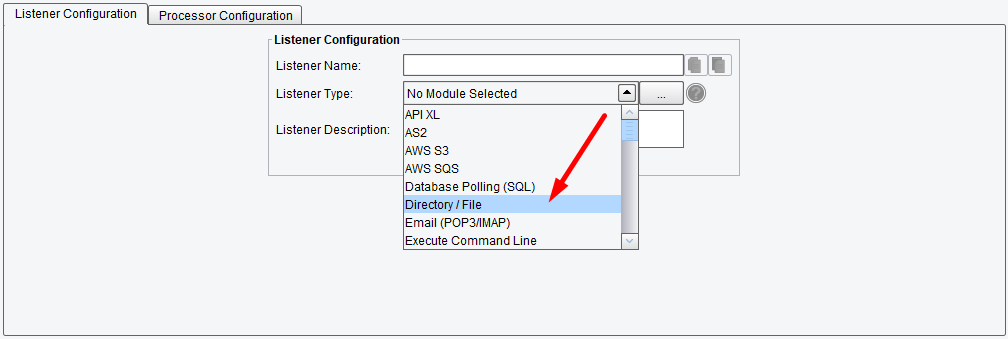
Here you selected Directory /File. Once a Listener type is selected you’ll be presented with a set of configuration panels. Those panels containing required configuration information are denoted by a red ball. Each configuration item that’s required is also denoted with a red ball.

Click the Basic configuration tab. In the Polling interval configuration item, you’ll want to enter in a frequency for how often to poll the directory for new files. Enter 10 in the Polling interval configuration.

Next, click in the textbox to the right of the Polling directory.

This file-based configuration item will allow you to choose a directory to poll. Create a new folder called input. Ensure this folder is selected and click Open.
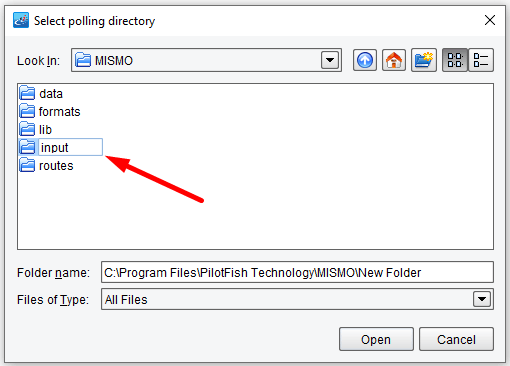
The full path to the Polling directory will appear in the Polling directory configuration. All other configuration information is optional so you can move on.

Configure Post-Process Operation.

Click on the Source Transform icon. The Source Transformation in an eiConsole interface is responsible for taking the data from the proprietary format of the Source System and converting it into a common or canonical format. Typically, in our industry, you’ll want to convert this data into a MISMO compliant format. To create a new transformation, click the Add Format button.

When prompted enter the name CSV-Applicants-To-MISMOCreditRq and click OK.

The Transformation tab will appear. You’ll note that transformations have 2 pieces, a Transformation Module that’s responsible for taking the data and converting it into XML if it’s not XML already, and then an XSLT stage which is responsible for the logical mapping of the proprietary data into your canonical XML format.

In the tutorial-data folder of your distribution, you’ll see a file called applicants.csv. This comma-separated file is the input to your process. This is the data you’ll need to take and turn into an XML format.
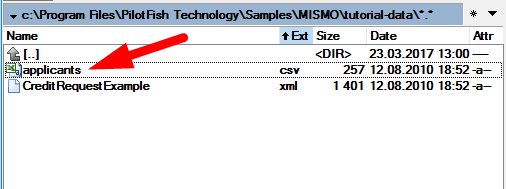
Reviewing this file in a text editor reveals that the first row contains column headers and each subsequent row contains data. You’ll need to take this data, convert it into XML, and then map it onto a MISMO Credit Request.

To convert this data into XML you’ll use the Delimited and Fixed-Width File Transformation Module. Select this entry from the Transformation Module drop-down.

Then, click the Edit button next to the File Spec configuration item.

This will launch the File Specification Editor. This tool is used to describe the Delimited or Fixed-Width file that you wish to parse. When creating a new File Specification you are immediately prompted with the Select for New File Type wizard. Since you want to import the field names from the headers of the CSV file choose Import Field Names from CSV File.

Then click Next.

The Field Delimiter is appropriately initialized with a comma so click Next again.

Now, in the Open File dialogue, you’ll need to locate the sample file that you pulled up in the text editor before. Navigate to the applicants.csv file in the tutorial-data folder and click Open.
When prompted to load the test file click Yes.

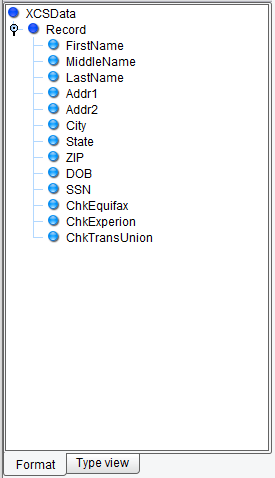
You’ll note two things. First, on the left-hand side a tree was created representing the logical structure of your inbound CSV. A green node depicts the Record type within the file, there is one Record type. The blue nodes represent each field, or columns, within the file. Field names were taken from the headers within that file.

You’ll also note the complete contents of the CSV file have been loaded into the Results preview tab.
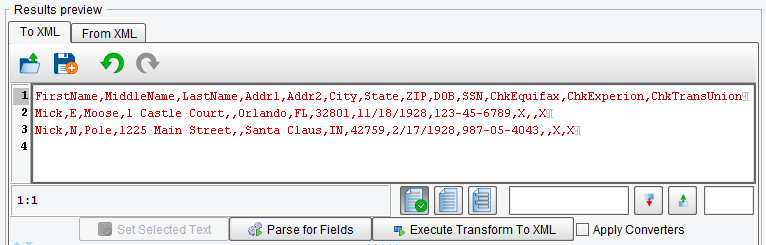
When using the File Specification Editor, the developer’s job is to build the tree on the left-hand side. In this case, you imported this information; but you just as easily could have gone in and added fields and records manually (use the right click of your mouse).

Once this definition has been built you can test to see how the file was parsed. To do that, with a sample file loaded in the To XML pane, click Execute Transform to XML.

A tree will appear below depicting the structure that you’ll parse this file into. You’ll note that it’s located 3 Records. The first contains the headers. The second and third were correctly parsed with the actual data fields.
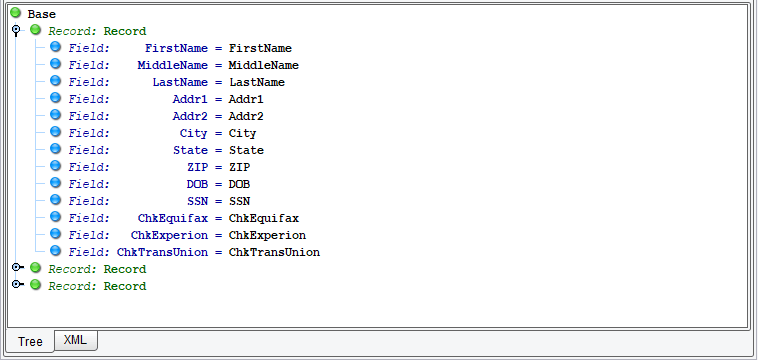
To avoid the extraneous parsing of the first Record, click the First row is headers checkbox at the top.

Click Execute Transform to XML again. You’ll note that only 2 Records are parsed.

If you were working with a Fixed-Width file it would become more likely that you might have some type of error within the parsing logic. To be able to review how the system parses a particular type of record you can select a sub-set of your sample file, click on a corresponding Record type from the tree on the left, and click the Set Selected Text button.

Now, as you navigate through each one of the fields underneath that Record, the corresponding section within the selected sample will be highlighted.
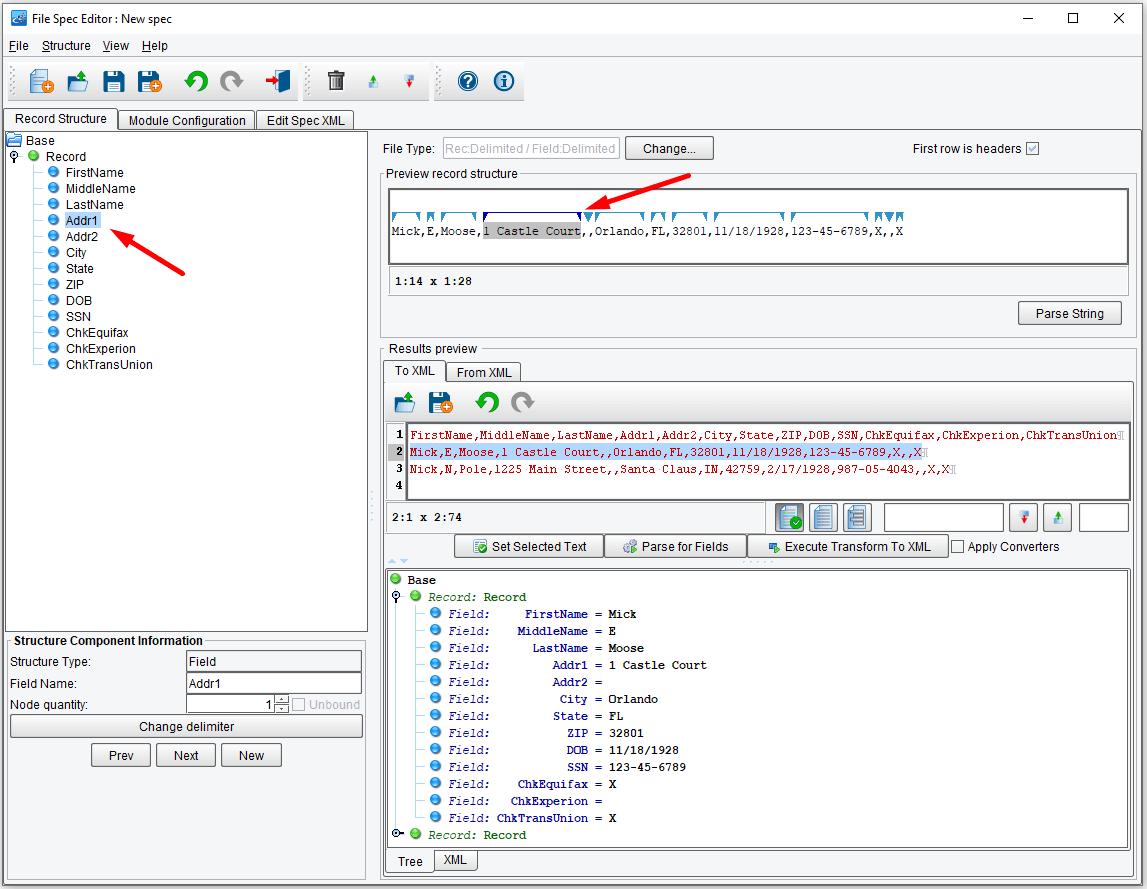
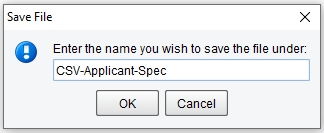
If modifications to the field definition need to be made, they can be made by dragging the blue arrows around or modifying the information beneath the Record structure tree. Since this parsed properly you can save your File Specification and move on to the next stage. Click the Save icon.

And enter the name CSV-Applicant-Spec and click OK.
Then, click the Return to Console icon.

Your next step is to build the logical mapping from your CSV file into the MISMO format. To do this, you’ll need to use the Data Mapper to build the logical mapping between the two formats. Uncheck Use Direct Relay.
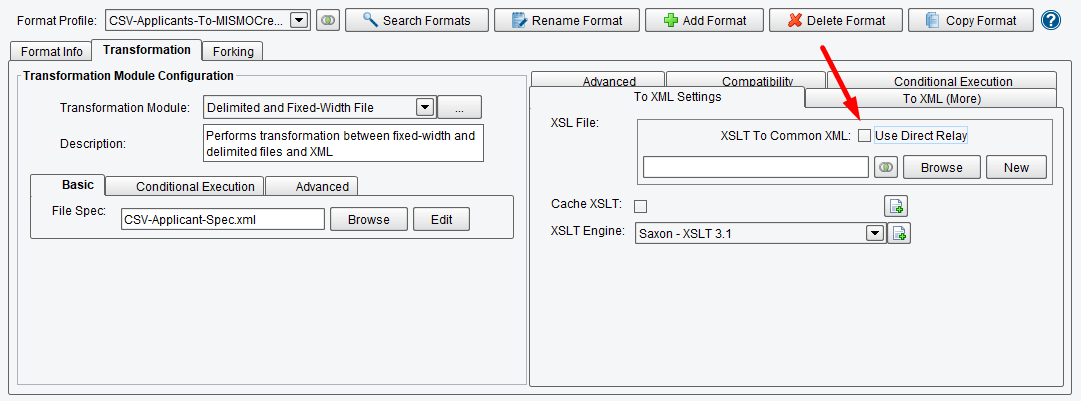
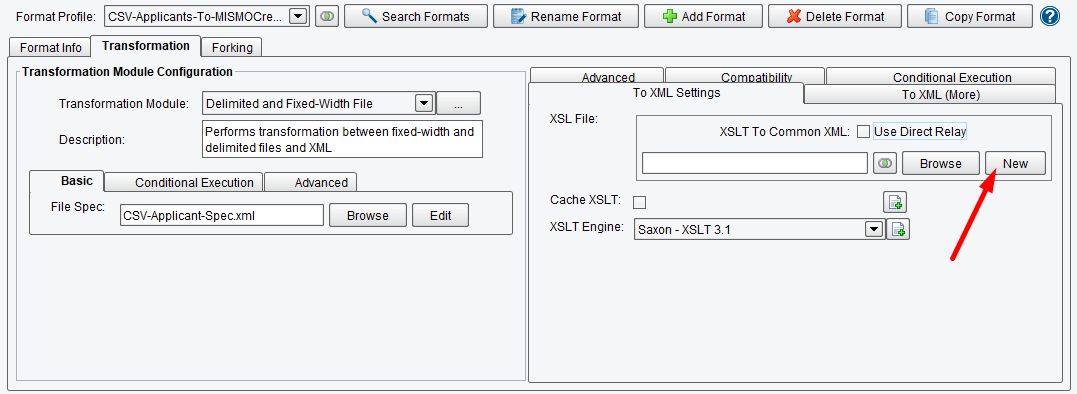
Now that you’ve completed specifying the format of your input CSV, you need to map that using XSLT onto the canonical model, which in this case is the MISMO Credit Request. All logical mapping within the eiConsole is handled via XSLT and the Data Mapper. Click the New button in the XSLT Configuration area to launch the Data Mapper.
The Data Mapper has three panes: a pane on the left-hand side which will contain the structure of your Source data, a tree on the right-hand side which will contain the structure of your Target format, and then a panel in the middle, which will represent the logical mapping between the two. Under the covers this is XSLT.
Start by clicking the Open Source Format icon above the Source Format tree.

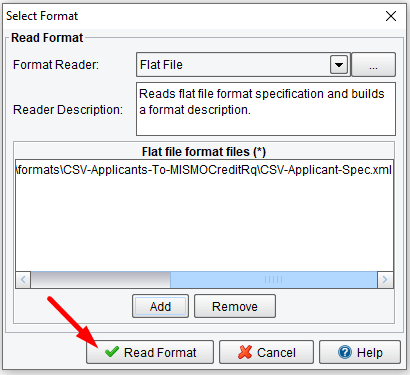
When the Select Format dialogue appears, choose the Flat File format reader. This will allow you to use the File Specification that you built during the previous stage to describe the structure of your input file. Similarly, you could use an XML schema, XML file, database, wizdal, etc.
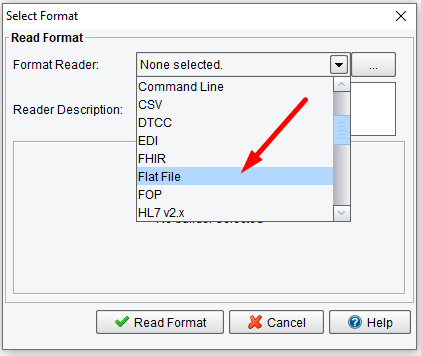
Once you’ve selected the Flat File format reader from the drop-down, you’ll be presented with a list of Flat File format files. Click the Add button underneath this area.

And then navigate to the formats folder underneath your working directory. You should see a CSV-Applicants-To-MISMOCreditRq folder.

Choose the CSV-Applicant-Spec.xml file and click Open.

Then click Read Format.
A tree will appear on the left-hand side that is very similar to what you just worked within the File Specification Editor.
Now, on the right-hand side, you’ll want to load the MISMO Credit Reporting standard. Click the Open Target Format button above the Target tree.
But this time, choose the XSD (Schema) format reader.

You’ll be prompted to provide a Schema file. You’ll want to use the Credit Request schema as published by MISMO. This may or may not be included with your distribution. If it’s not included, you can find this in the Credit Reporting section of MISMO.org in the specifications area. Click the Browse button.

Locate the specification folder, then choose the CREDIT_REQUEST_v2_4_1_1.xsd and click Open.

Now click Read Format.

Choose the REQUEST_GROUP and click OK.
 A tree representing the Credit Request standard will appear on the Target side. As you navigate the tree, you’ll notice the Doc tag includes any documentation included within the MISMO schema.
A tree representing the Credit Request standard will appear on the Target side. As you navigate the tree, you’ll notice the Doc tag includes any documentation included within the MISMO schema.

The next thing you’ll want to do is create the skeletal structure of the transaction that you want to map to. This could be done by dragging elements from the right-hand side into the center. But, when working with a large file, that can become laborious. Instead, you’ll load a sample and use that to seed your mapping. Click the View Sample Data button above the Target tree.

Then, click the Load Sample data icon.

In the tutorial-data folder, you’ll see a CreditRequestExample.xml. Select this file and click Open.

This is a sample MISMO stream taken from the Credit Request implementation guide. Click the Close button.

Now, to use that sample data to seed your mapping, under the Formats menu choose Add Target Sample Data As Template.

When prompted to load the values from the sample into the mapping click Yes.

A number of green nodes, or Target output, should be created within the tree, along with the blue node at the root. Each green node represents an XML attribute or element that will be created when the transformation is run. Now change Record to XCSData. Input it and hit Enter.

The blue node, XCSData at the root indicates that this will occur for each XCS Data element in your input.

Now, let’s map a few fields. If you were to run this right now what would be created would be completely static. The output would be essentially the Target format sample data. What you’ll want to do is replace some of the hardcoded things within the sample with dynamic values taken from the Source. Leave the REQUESTING_PARTY and RECEIVING_PARTY alone. You can collapse those nodes to get them out of the way. In the REQUEST element, you’ll note that the first attribute is the RequestDateTime. You’ll want to replace this hardcoded value with the actual Current DateTime that the transformation was run. To do this you’ll use the pallet of functions above the center mapping. Select the Custom tab and the Date sub-tab. Then locate the Current DateTime tool.
Click this and drag it on top of the RequestDateTime attribute. The hardcoded value is replaced by a syntax that indicates that you want to take the Current DateTime and use it to populate this attribute.
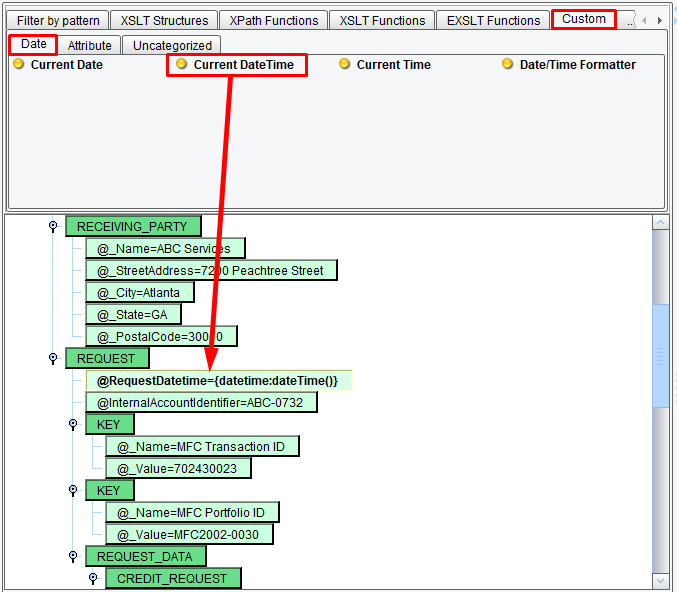 The second attribute is an InternalAccountIdentifier. Let’s say you want to replace this hardcoded value with a hardcoded value of your own. To do that, double click on the InternalAccountIdentifier attribute, select the existing value and enter one of your own: SomeValue12345. When you’re done hit Enter. It’s important to hit Enter as opposed to Escape or just clicking off of a node within a mapping. Navigating away from a node without clicking Enter will replace the value with its previous value.
The second attribute is an InternalAccountIdentifier. Let’s say you want to replace this hardcoded value with a hardcoded value of your own. To do that, double click on the InternalAccountIdentifier attribute, select the existing value and enter one of your own: SomeValue12345. When you’re done hit Enter. It’s important to hit Enter as opposed to Escape or just clicking off of a node within a mapping. Navigating away from a node without clicking Enter will replace the value with its previous value.

Next you’ll see a couple of KEY elements. Let’s say that your implementation does not require either one of these KEYs. Click on the KEY node, then right click and select Delete. Repeat this process with the other KEY node.
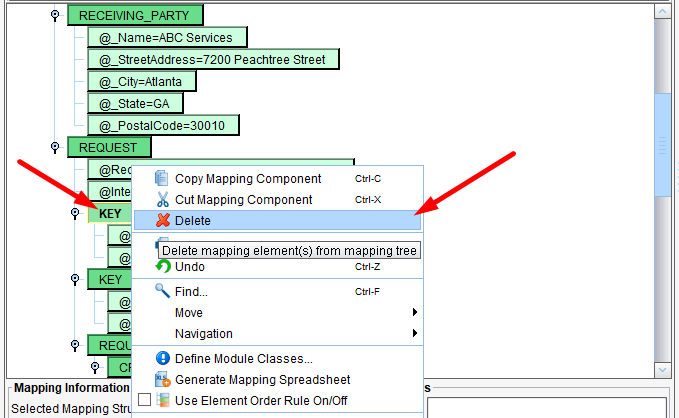
The KEY elements and all of its children will be removed from the output. Now you’ll move on to the REQUEST_DATA section. You’ll want the REQUEST_DATA section to repeat for each record in your input. To accomplish this you’ll want to use the XSLT for-each structure. Select the XSLT Structures tab and the Flow Control sub-tab. Then, locate the for-each icon. Drag the for-each icon between the REQUEST and the REQUEST_DATA nodes. You’ll know you’re in the right place when there is a bar above REQUEST_DATA and REQUEST is highlighted.
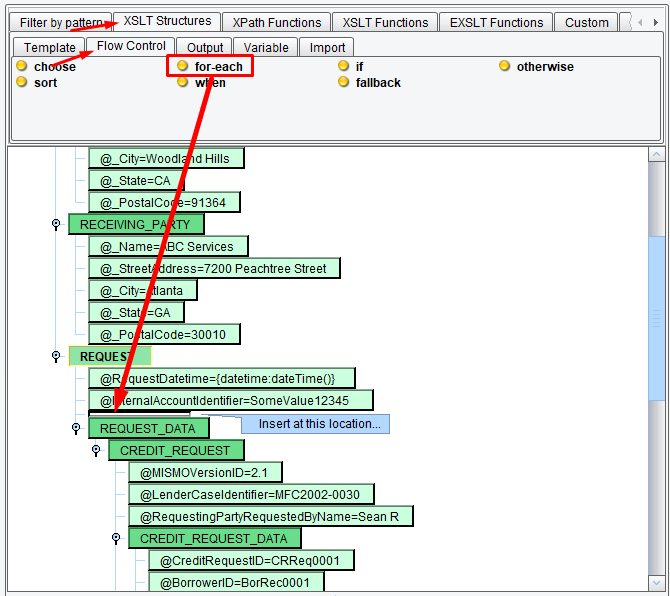
A blue for-each node should appear.

Since you want the REQUEST data to repeat for each inbound record, you’ll select Record from your Source tree and drag it on top of the for-each.
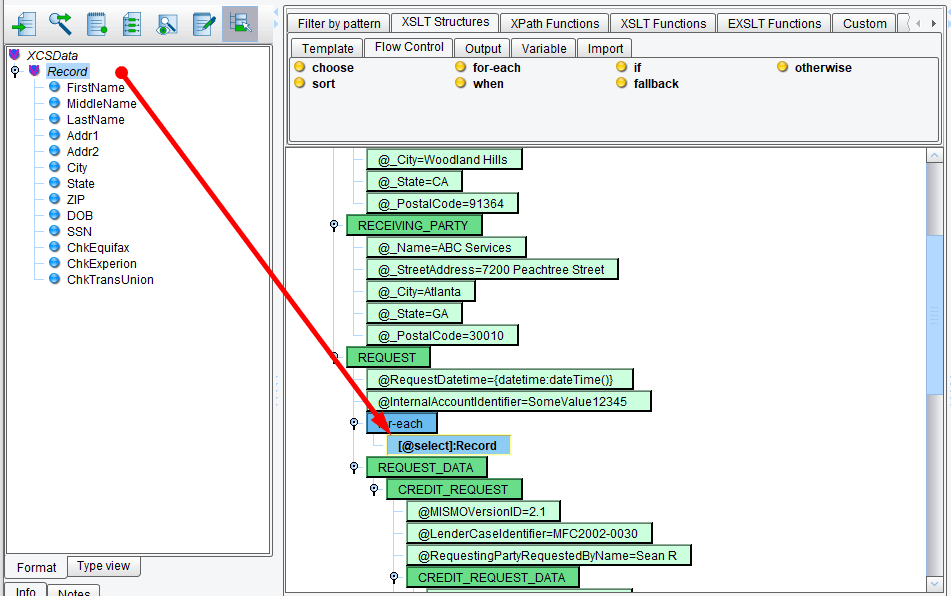
Next, you’ll take the REQUEST_DATA node, the node that you want to repeat for each Record, and make it a child of that for-each. Select the REQUEST_DATA node and drag it on top of the for-each.

Now the REQUEST_DATA node is a child of for-each.

Let’s move on to the LOAN_APPLICATION node underneath the CREDIT_REQUEST. Expand LOAN_APPLICATION and expand BORROWER. Let’s map each of these nodes from the top down. Beginning with the BorrowerID, map the BorrowerID to the SSN. Select SSN from the Source record and drag it onto the BorrowerID attribute. A simple one-to-one mapping will be created replacing the hardcoded value.
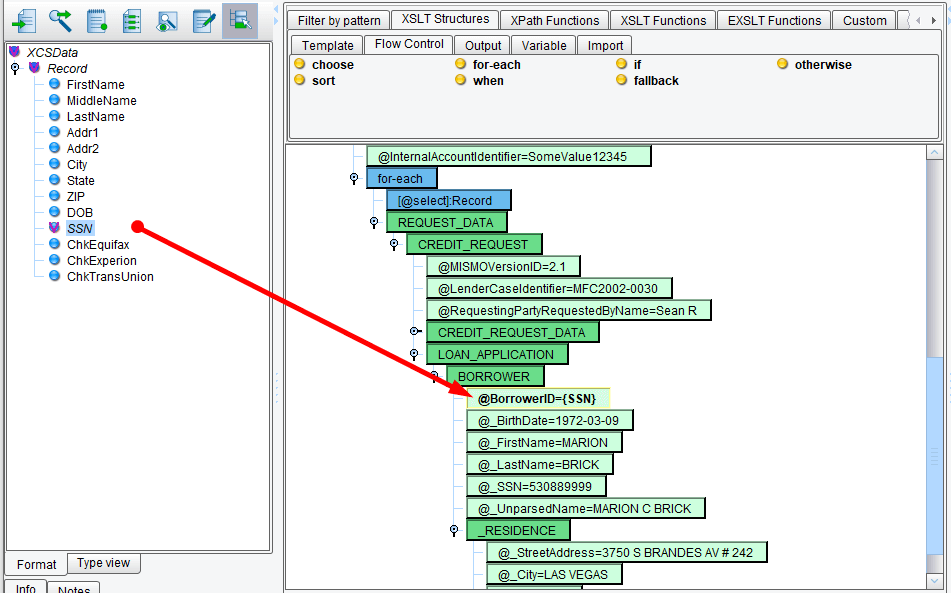
Let’s skip birth date for a minute and map FirstName and LastName. Map FirstName from the Source to the FirstName attribute and LastName from the Source to the LastName attribute. Also, map SSN to SSN.

Next, you’ll see BirthDate and UnparsedName require mapping. First look at the UnparsedName. You’ll want the UnparsedName to be a concatenation of your FirstName, MiddleName, and LastName with spaces in between. One way to do this is double click the Attribute, highlight the hardcoded value, and then enter in:
{concat(FirstName,' ', MiddleName,' ', LastName}
That is one way to enter in a dynamic value.

You can also use functions from the pallet above and variables. Let’s do that with the BirthDate that requires a little more formatting. You’ll note that the sample in the MISMO XML is in yyyy-MM-dd format. However, your input CSV file uses MM/dd/yyyy. Let’s create a variable to handle this transformation. In the XSLT Structures tab, the Variable sub-tab, choose the Variable tool. Create a variable node directly under the BORROWER.
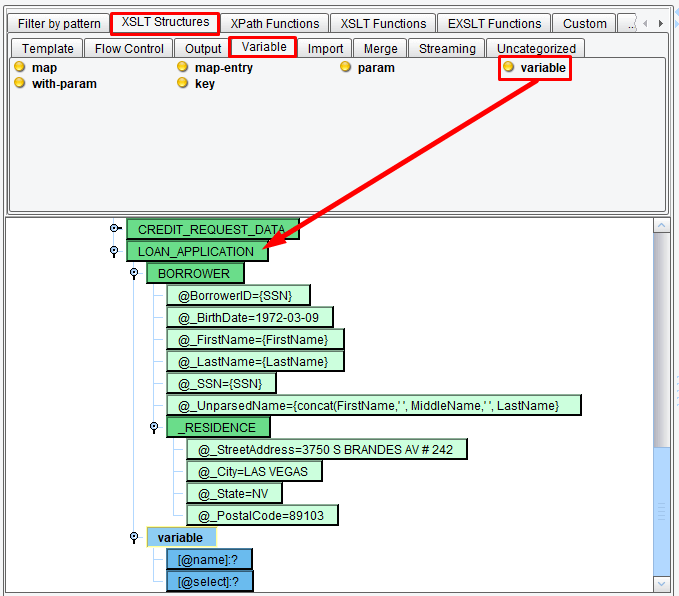
Select the Variable node and move it up above the BORROWER node using the Move mapping component up… button.

Double click on the name and enter formattedDOB.

Next, you’ll want to map the DOB onto the formatted DOB variable. Drag DOB from the Source record onto the formatted DOB select Attribute.
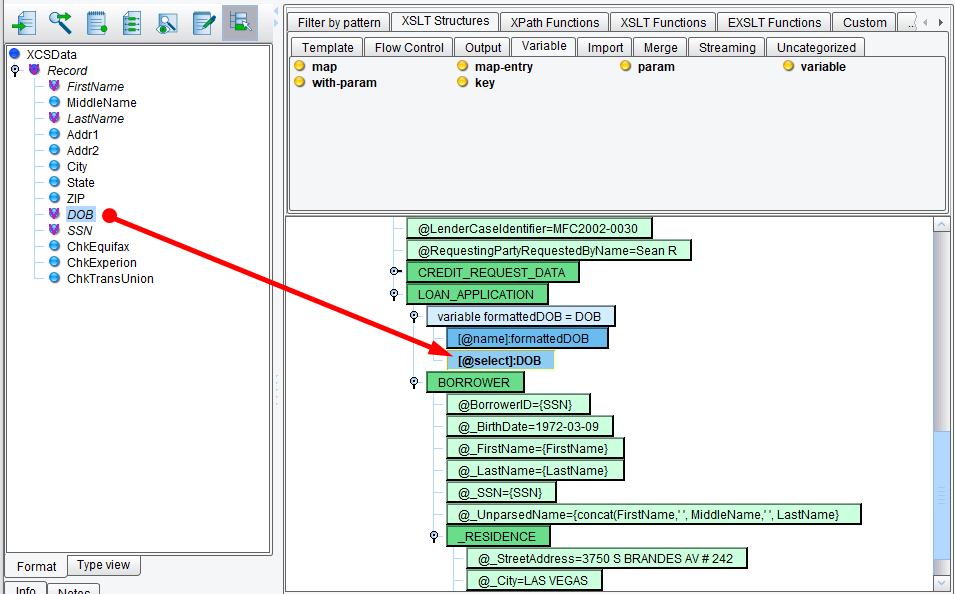
Next, you’ll need to actually format the date of birth. From the Custom tab, Date sub-tab, choose the Date/Time Formatter and drag it on top of the DOB.

The Add Date/Time formatter dialogue will appear. Enter your expected input pattern (MM/dd/yyyy) and your expected output pattern (yyyy-MM-dd). Note the capitalization matters here and that a sample of the pattern will appear to the right using the current date and time. Once complete, click OK.

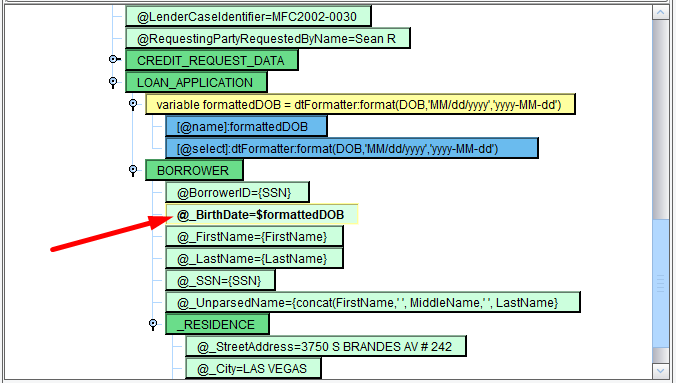
You now have your reusable formatted DOB available for you.

Now, double click on the BirthDate Attribute and in the Value text area replace the hardcoded value with $formattedDOB and hit Enter. The dollar sign preceding a name is used to reference a variable that you created earlier in the document.
Now you’ll move on to the RESIDENCE area. Expand the RESIDENCE section. You’ll need to map StreetAddress, City, State, and PostalCode. These all have straightforward mappings from the Source. Now drag & drop: Addr1 to StreetAddress, City to City, State to State, ZIP to PostalCode.
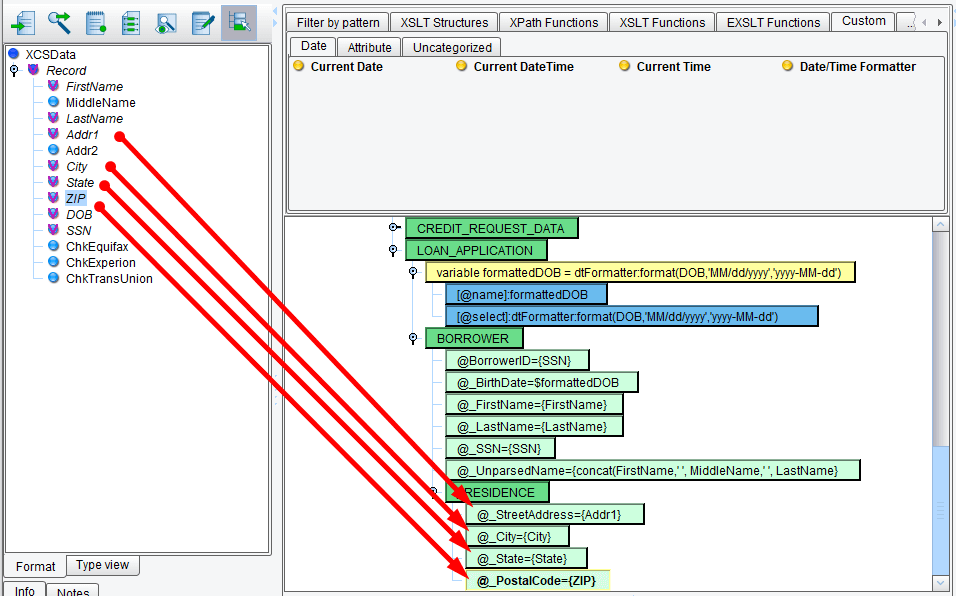
However, you’ll notice that your Source has Addr2, a second line of the address, which isn’t accommodated in this RESIDENCE block. However, you can take a look at the MISMO standard to see if an optional attribute is available for your use. To do this, you’ll navigate through the Target tree to the RESIDENCE node underneath the borrower. Note that as you navigate through the tree any field that has documentation has a Doc tag associated with it.
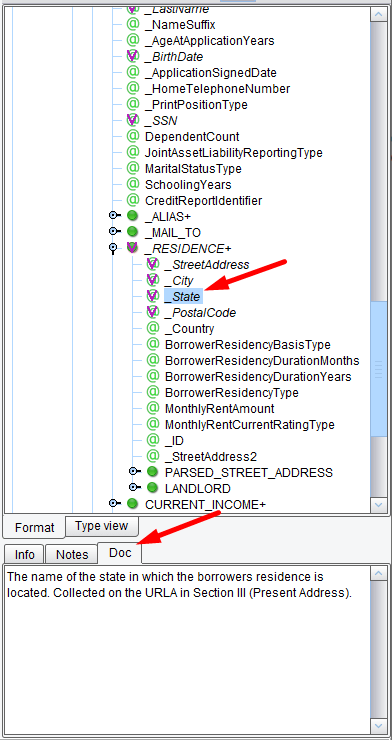
Underneath the RESIDENCE you’ll see StreetAddress2. Take this Attribute and drag it on top of the parent RESIDENCE node. A new StreetAddress2 Attribute will be added to your output.
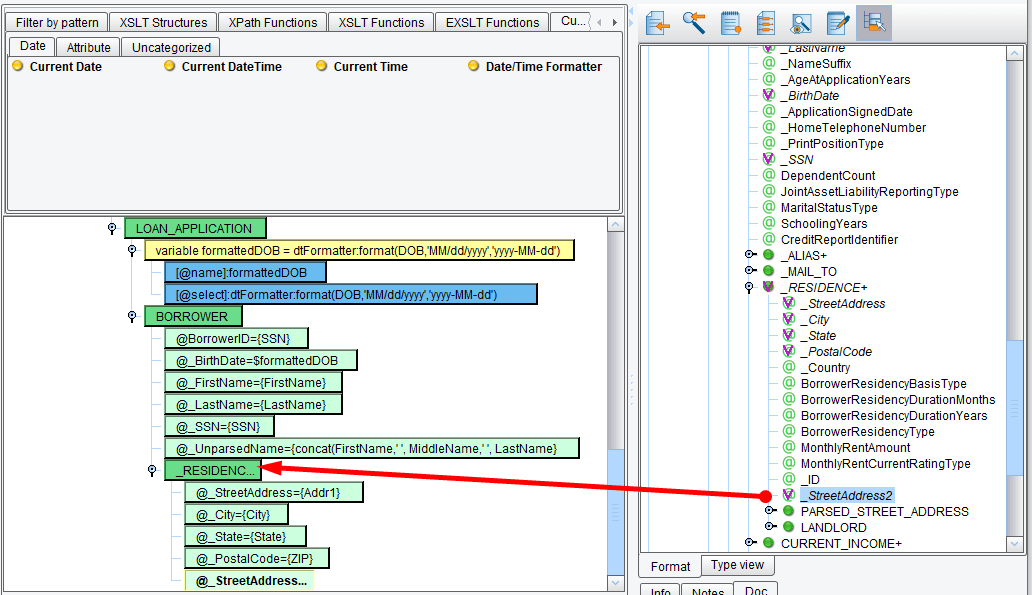
However, it hasn’t yet been mapped. As you did with everything else, drag Addr2 onto the StreetAddress2 Attribute.

You’re almost done. You’ve come to the bottom of the mapping, but you’ll notice that you have an indicator to determine which of the three credit reporting bureaus you wish to check. This information needs to be mapped into the CREDIT_REPOSITORY_INCLUDE aggregate, which has an Equifax, Experian, and TransUnion indicator. First, map the ChkEquifax field onto the EquifaxIndicator in your mapping.

Now, your sample data will include an X if you want to check that bureau, or it will be clear or have a different value if you don’t want to check it. Therefore, you’ll need to map from X to the expected value of Y, or from any other value to an N. To handle this type of look-up type mapping, you’ll use the Tabular Mapping tool. Underneath the Custom tab in the Uncategorized sub-tab is a Tabular Mapping icon. Drag this tool onto the Equifax indicator.
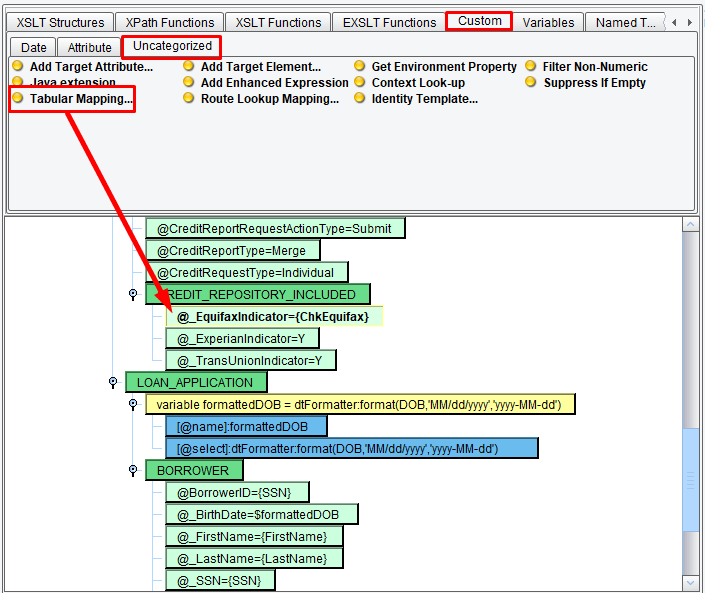
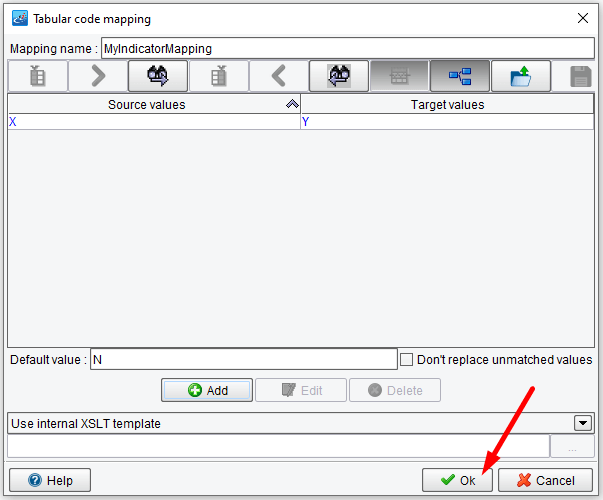
Then click Define New.

This will allow you to create a new type of mapping. Let’s call this MyIndicatorMapping. Enter this under the Mapping name.
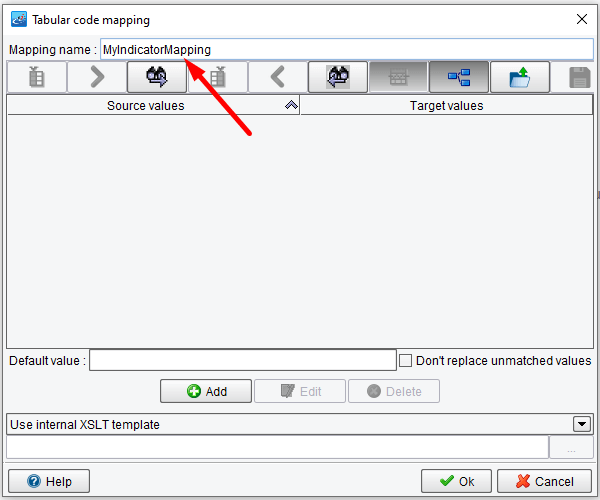
Since you want the Default value to be No, enter N in the Default value area. To enter in the mapping from X to Y, click the Add button.
 In the Source textbox type X. In the Target textbox type Y. Then click Ok.
In the Source textbox type X. In the Target textbox type Y. Then click Ok.

The grid will be populated with one row representing a Source to Target mapping. Note that this grid can contain any number of values. Once you’ve completed this step click Ok.
Choose MyIndicatorMapping and then hit Select.

All of the code required to call out to that mapping to populate the Equifax indicator will be populated into your center mapping.

You now need to repeat this process with the Experian and TransUnion indicators. Map ChkExperian and ChkTransUnion onto the corresponding Attributes underneath CREDIT_REPOSITORY_INCLUDED.

Now, again drag your Tabular Mapping tool onto first the Experian indicator. This time, when prompted to choose a Tabular Mapping, choose the one that you just created, MyIndicator Mapping and hit Select. Do the same for TransUnion.
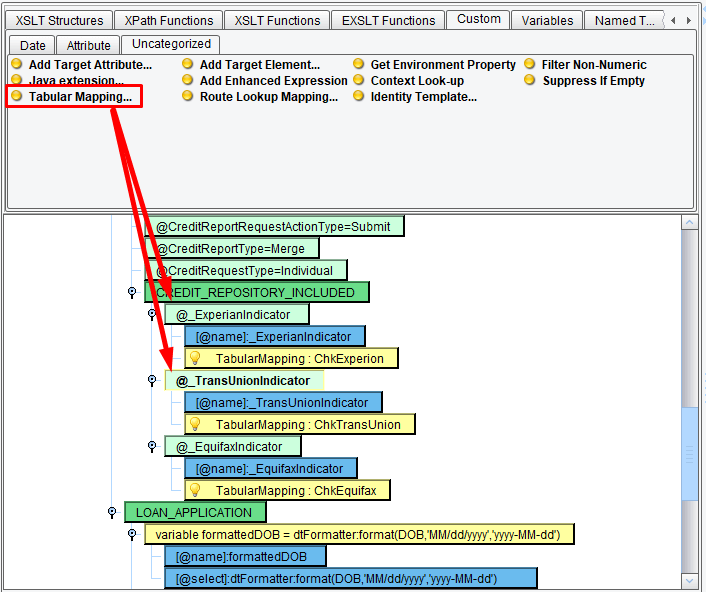
You’ve now completed your logical mapping from your CSV format onto a MISMO CreditCheckRq. Click the Save Current Mapping icon.

And provide a name for your XSLT. Call it CreditRqFromCSV and click OK.

Then click the Return to Console icon.
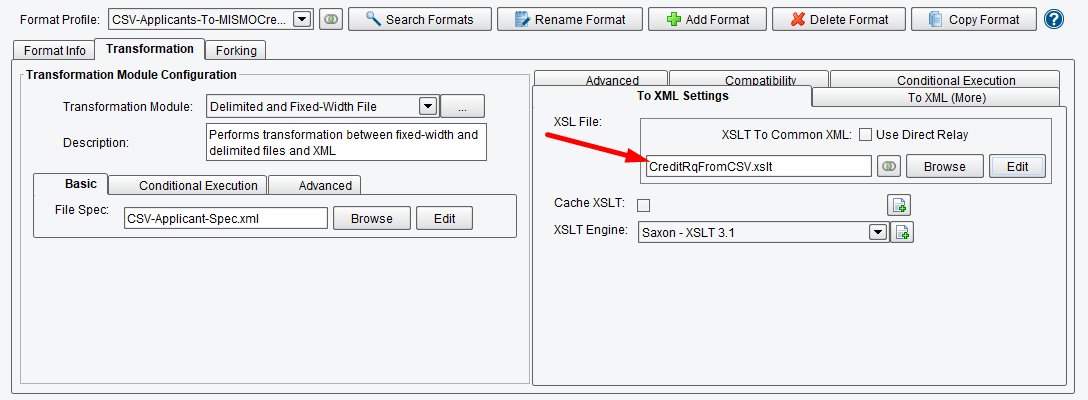
You’ll note that the XSLT file you just created is automatically populated into the XSLT Configuration area.
Next, click on the Routing icon. In this stage, if you had multiple, different Target Systems, you would be able to configure Routing Rules. This would allow you to inspect XPaths or Attributes of the inbound data, and based on that, determine which Target Systems to send the data to.

In this case you’re sending the data along to all defined Targets, the one Target that you’ve created.

The Routing stage is also where you configure Transaction Monitors. Click on the Transaction Monitoring tab.

Choose Add Transaction Monitor. Transaction Monitors are the eiConsole’s mechanism for proactive error reporting, whether it be an email to operations staff, an SNMP Trap for a piece of monitoring software, or an Error Route Trigger to invoke another route or interface to handle the error. This is how you set up that type of proactive response to an unexpected error condition. In this case, you won’t configure Routing Rules or Transaction Monitoring and will just move on to the Target Transform.

The Target Transform is where you’ll take the data from your canonical format and lay it out into a format that the Target System can mostly easily consume. If the Target System can consume the standard that you’ve provided (it’s on the same version, uses the same interpretation), no further translation is required here. However, if you need to go between versions or interpretations, or if you need to layout the file completely differently so that the Target System can consume it you would add a new Format. To add a new Format, click the Add Format button.
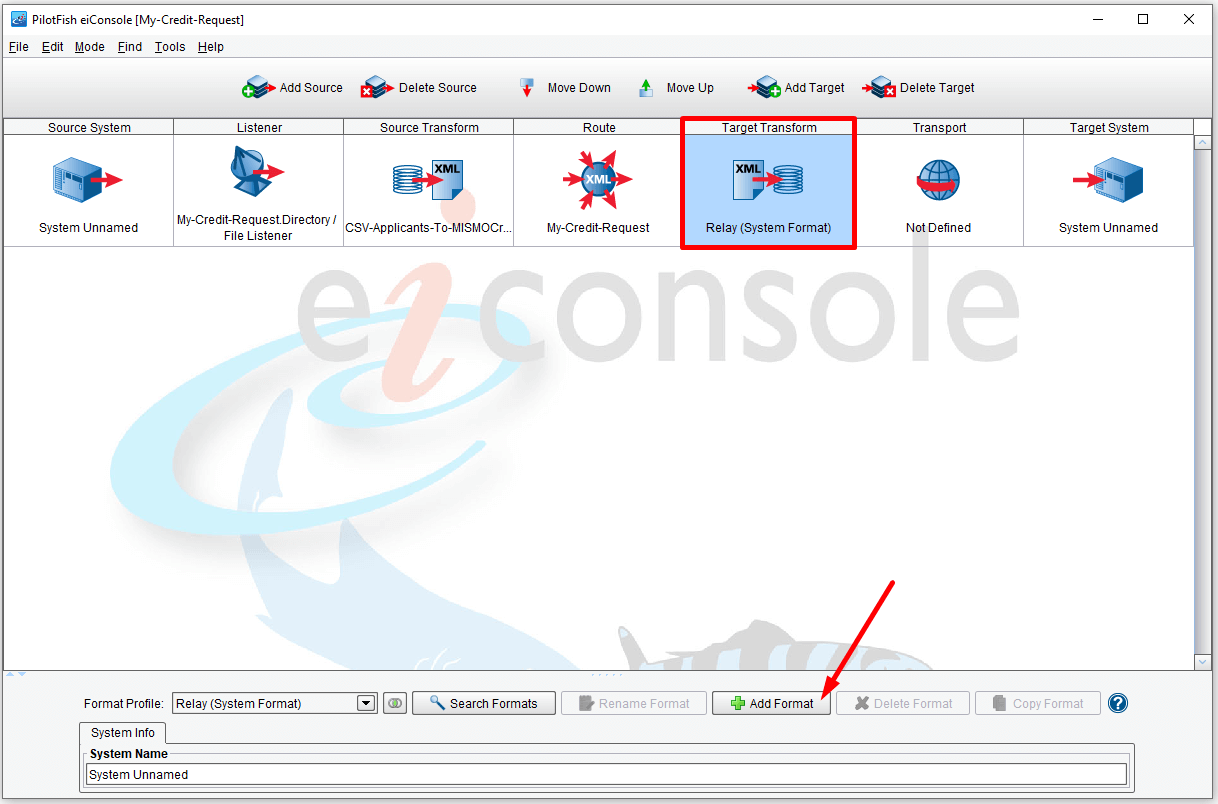
Click it and add the name CreditCheckFormat and hit OK.

Now, a default transformation won’t do anything further. It will just take the data and pass it along to the next stage. That’s what you’ll leave it for now.

Next, click on the Transport icon. The Transport stage is very much the mirror image of the Listener. There are a number of different Transport Types that allow you to handle connectivity to the Target System. This connectivity could be batch-oriented, it could be real-time, and it could be something that is asynchronous or synchronous.

In this case, you’re just going to drop the file into a directory, so choose Directory / File from the Transport Type drop-down. For the Target Directory, you’ll create a new folder on the local drive. Click the button next to the Target Directory.

Create or select a folder called output.

In the Target file name area, enter the name of the file that you wish to create. Let’s call it MISMOCreditRq. In Target file extension configuration item you’ll need to enter the extension that you wish the file to be created with. Since it’s an XML file enter xml.

Now you’re pretty much done. The Target System will receive the data and handle it however it needs to. What you can do now, however, is go back in and apply some Metadata to the Source and Target systems. The Metadata is purely informational, but it will help you get a sense of what an interface is really doing.
Click on the Source System and enter in Loan Application and choose an icon.

Then, click on the Target System and enter Credit Bureau and choose an icon.

You’ve now completed configuring the topology of the interface. To save your work, under the File menu select Save Current Route.

Then, under the Route menu, click Testing Mode.

In Testing Mode of the eiConsole, you can test any number of different stages of the interface together or an individual stage. The green and blue arrows will indicate the stages of the test that you want to run with the green arrow indicating the starting point.

By default, a test will begin at the Listener and run through to any defined Transports. However, let’s start by just testing your transformation. To do that, click on the Source Transform stage. In the Objects within selected stage grid select Start Test Here within the Stage Configuration area and select From File item from Alternate Data Source drop-down menu.

Then, click on the XSLT sub-stage and click End Test After Here.
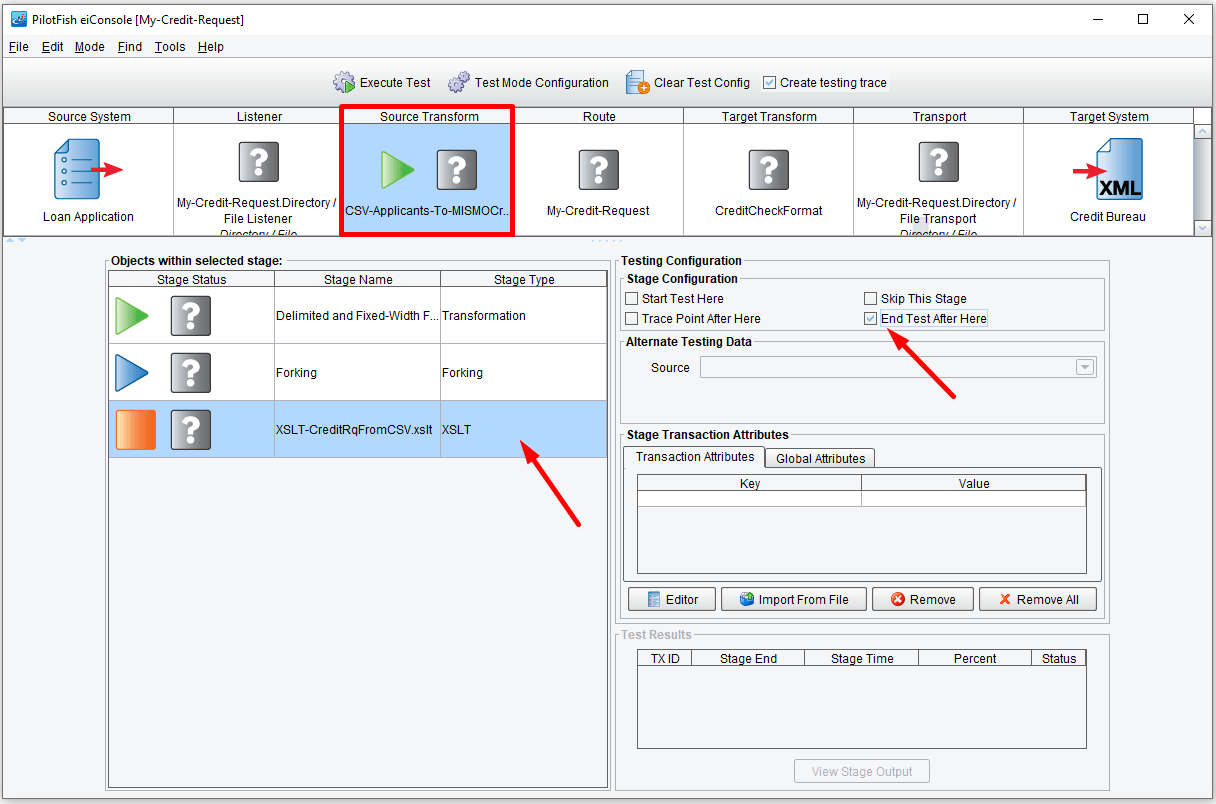
You’ll see that now only the Source Transform has an arrow associated with it. In the Objects within selected stage area, you’ll see a green arrow indicating that you’ll start with your File Specification change, taking the CSV file and converting it to XML, continue with an unused forking stage, and complete after having executed the XSLT, the mapping of the XMLized CSV onto the MISMO CreditCheckRq.
Click the Execute Test button.

When you do this you’ll be prompted with a dialogue asking you to provide a sample file to start the test with. Choose the CSV file in the tutorial-data folder and click Open.

As each stage completes you’ll either see a green checkmark or a red X. A checkmark indicates success, a red X indicates failure.

With the starting stage selected you can also hit the View button in the Stage Configuration to see your input.

Here the input looks fine.

Next, double click on the Delimited and Fixed-Width file stage from the Objects within the selected stage grid. This will show you the data as it appeared after being translated to XML. Again, this looks like it was parsed appropriately.

Now, click the red X on the XSLT stage. You’ll see that you have an error.

Since the error is in the XSLT stage, you’ll want to save the input that went into that mapping, return to the Data Mapper, and debug. To do this, click the stage immediately preceding the Data Mapping.

Double-clicking will bring up the stage output viewer. Click the Save Results icon.

Name the file applicants.xml and click Save.

Now, you’ll want to return to Editing Mode by choosing Route, Editing Mode.

Click on your Source Transform and in the XSLT Configuration area hit Edit. This will again launch the Data Mapper. Now you’ll want to test the XML input right within the Mapper. Click on the Testing tab.
In the Source area click the folder icon.

This will allow you to choose a Source XML file. Choose the applicant.xml file that you just saved aside and click Open.

Then, to execute the XSLT against your sample, click the Execute Transformation button, the green triangle in the upper left.

You’ll see the detailed error message appear in the Output area.

If you click on the XSLT view you’ll also see the error line highlighted. You can see there’s a typo in the unparsed name attribute. When you manually typed in the concatenation function you forgot a cold, closing parentheses.

Add that parentheses within the XSLT view and return to the Testing view.

Click the Execute Transformation icon again. This time you’ll see your transformation complete successfully. Save your changes and return to the Console. Now, go back to Testing Mode and try again. Under the Route menu Testing Mode. If prompted, save the route changes. Click on the Source Transform and choose to start your test at the Delimited and Fixed-Width File Transformation Module. Choose the XSLT stage and to end your test after that point. Click the Execute Test button and provide your CSV sample. This time, all three of the stages complete successfully.

You can double click the XSLT Stage to view the output. You can see that you’ve created two REQUEST_DATA sections each with its own unique credit request and loan application info. Return to the Console.

Finally, you may want to do an end to end integration test incorporating both the Listener and the Transport. To do this, click the Clear Test Configuration icon.

Then, select the Listener stage and choose Start Test Here. Now, click Execute Test again. This time, rather than prompting you for sample data a dialogue will appear indicating that the Listener is engaged and waiting for data. In order to invoke the interface, you’ll need to take the sample data and copy it into your defined input folder. To do this, locate your applicants.csv file, copy it. And paste it in your defined input folder.

Within seconds the file should be deleted and green check marks should appear from left to right again across your screen. Click on the Stop button.
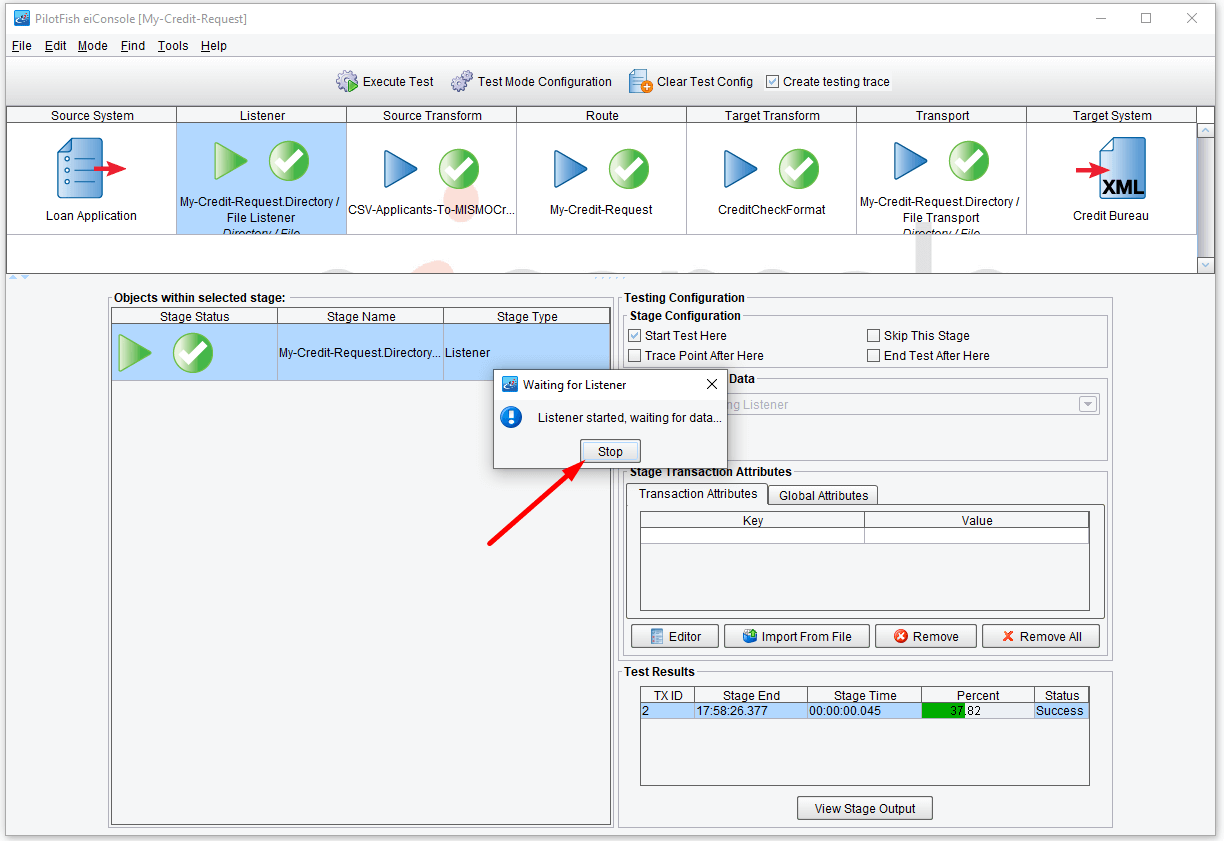
Now, if you navigate to your defined output folder, you should see the final output file created.


You’ve just completed building your first eiConsole for MISMO interface. To review, you created a Route in the File Management window. You then worked your way from left to right across a number of different paint-by-number stages configuring the behavior of the interface. You spent the most time in the Source Transform configuring first the structure of your input file in the File Specification Editor and then the mapping to your canonical format in the Data Mapper. In Testing Mode you united tested several stages and integration tested the full interface. Typically, the last step is to take your interface and the configuration files that it creates and deploy it to an eiPlatform server. Select File, File Management.

For more information on how to deploy an interface to the eiPlatform server, please consult additional documentation or the PilotFish website www.pilotfishtechnology.com. This completes the eiConsole for MISMO Getting Started Tutorial. We hope you’ve seen how quick and effective it can be at allowing you to create MISMO compliant interfaces between 2 heterogeneous systems or entities. Thank you very much and happy interface development!