eiConsole v.25R1
Tutorial & Interface
eiConsole – Data Mapping & Transformation
Using Keys for Deduplication in the Data Mapper
Note: The Quick Start, Foundation, and Topology tutorials should be completed before proceeding with the Data Mapping & Transformation Tutorials.
Overview
This interface and related tutorials demonstrate the use of the Data Mapper in Route configurations to transform between XML Formats. In this particular exercise, an existing Route (from “Data Mapping – Using Templates”) is modified to transform a “PeopleA” XML format to the “PeopleI” XML format. This mapping makes use of XSLT keys and the “Muenchian method” to perform deduplication during XSLT iteration. This tutorial expands on concepts covered in “Data Mapping Using Templates,” so users are expected to be familiar with that material.
Before You Begin
Working Directory
Download the Using-Keys-for-Deduplication-Working-Directory.zip file with the sample Working Directory and unzip it on your computer to a convenient place. In our case, it’s c:\Users\{USER _NAME}\PilotFish eiConsole Working Directories\Using Keys for Deduplication where {USER_NAME} is the user’s name.
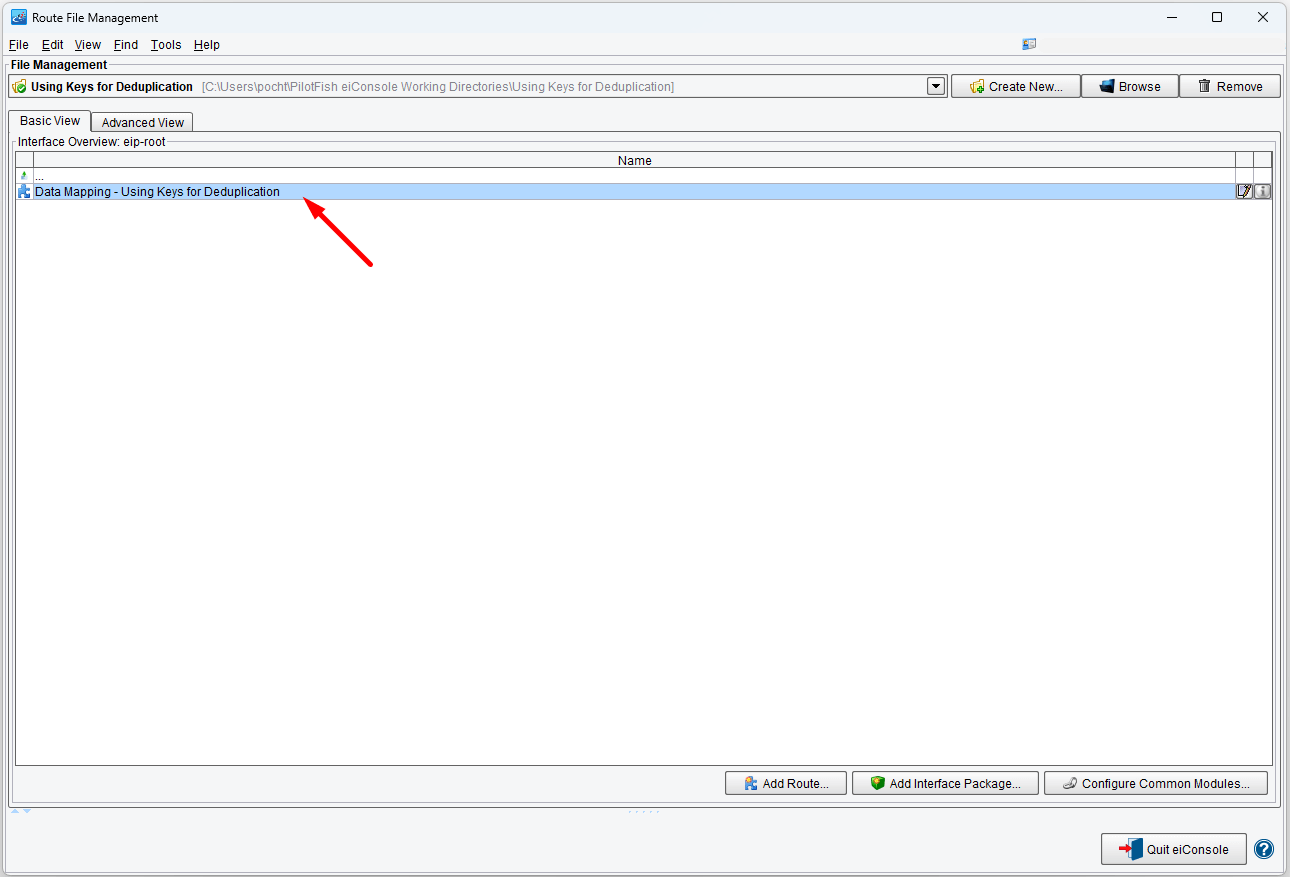
Open the eiConsole, browse to your Using Keys for Deduplication directory, and open it. The fully configured Data Mapping – Using Keys for Deduplication route is included in the Working Directory. Your Route File Management screen will open, as shown below.
Next, follow the tutorial and walk through it step-by-step. You may check your work against the provided Route sample data at the end.
Double-click on the Data Mapping – Using Keys for Deduplication
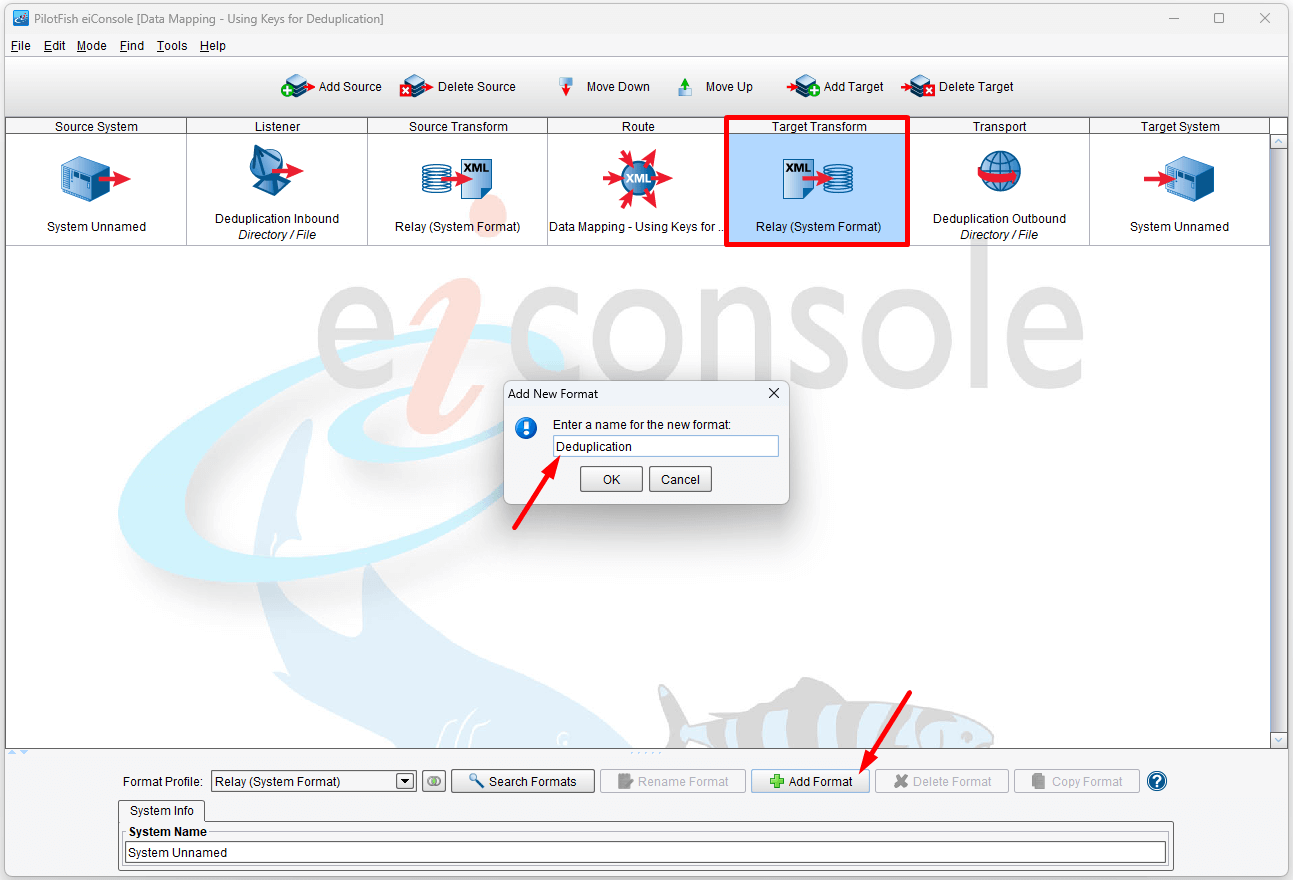
Creating & Configuring a New Format
Start by creating and configuring a new format. Name it Deduplication.
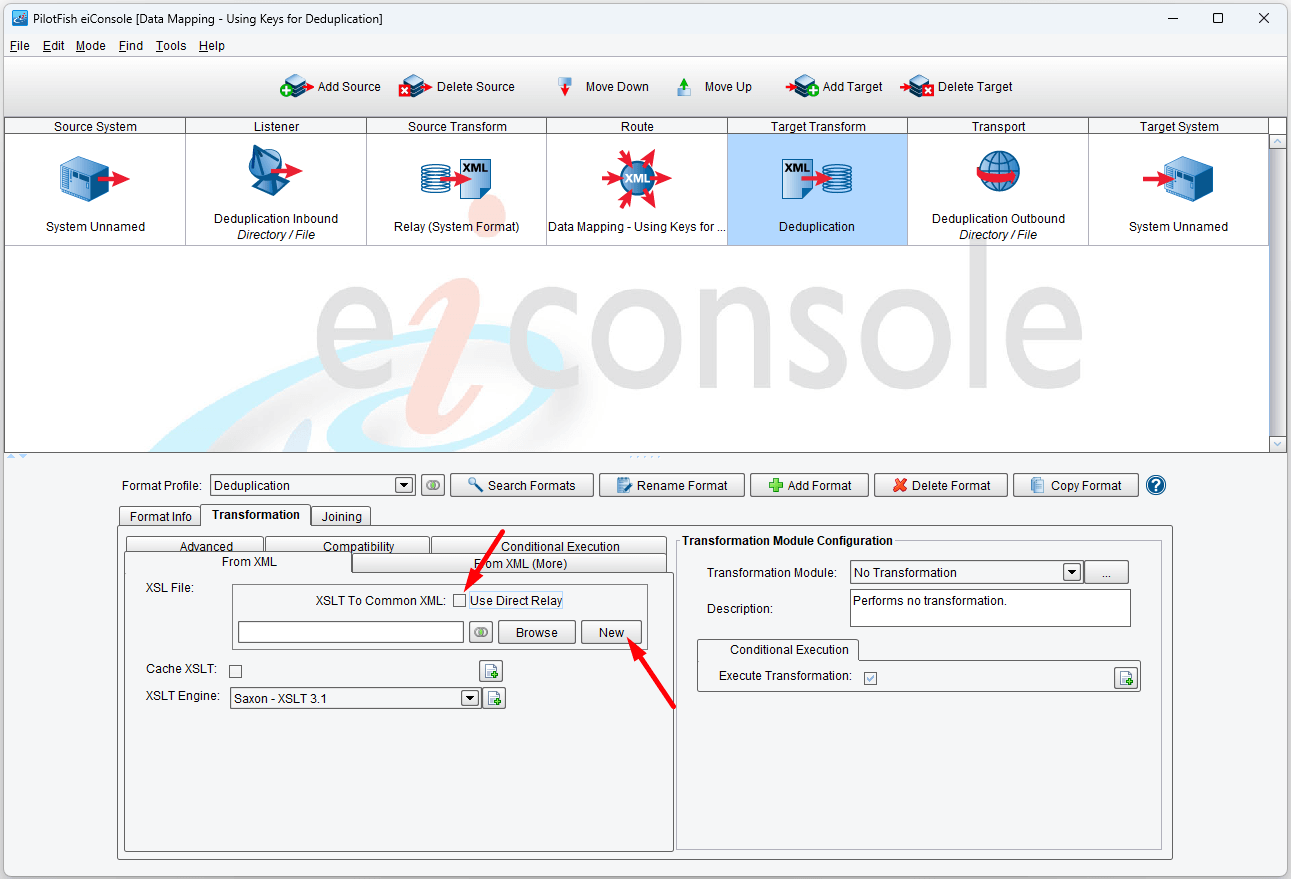
Uncheck the Use Direct Relay checkbox and click the New button to open the Data Mapper.
Then, using the Format Reader, select XML and read “PeopleA.xml” as the Source. You can find it in c:\Users\{USER _NAME}\PilotFish eiConsole Working Directories\Using Variables\data. The PeopleI.xml is also here.
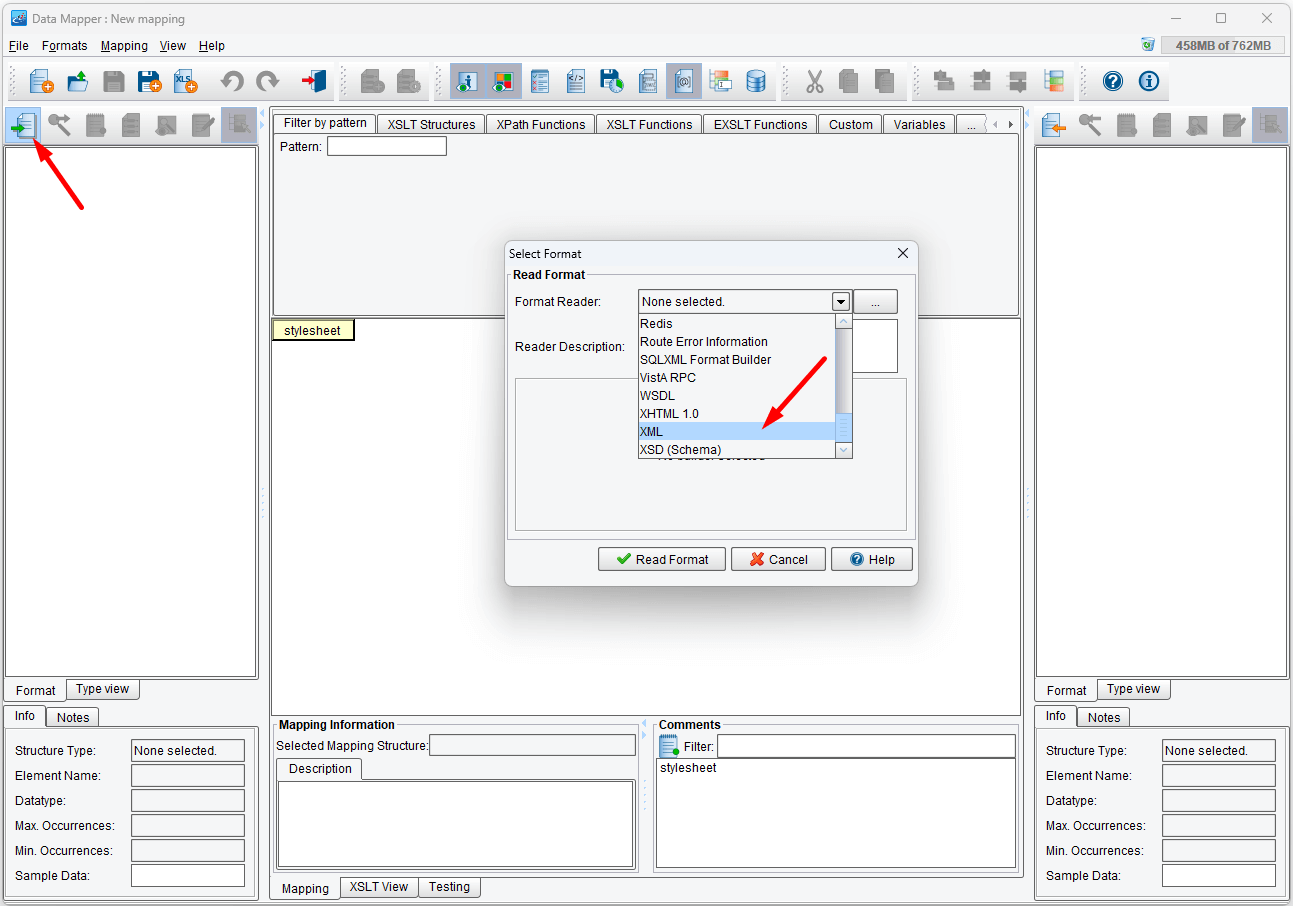
Click the Read Format button…
… and then read the PeopleI.xml as the Target.
Click the Read Format button.
Now your Data Mapper should look like below.
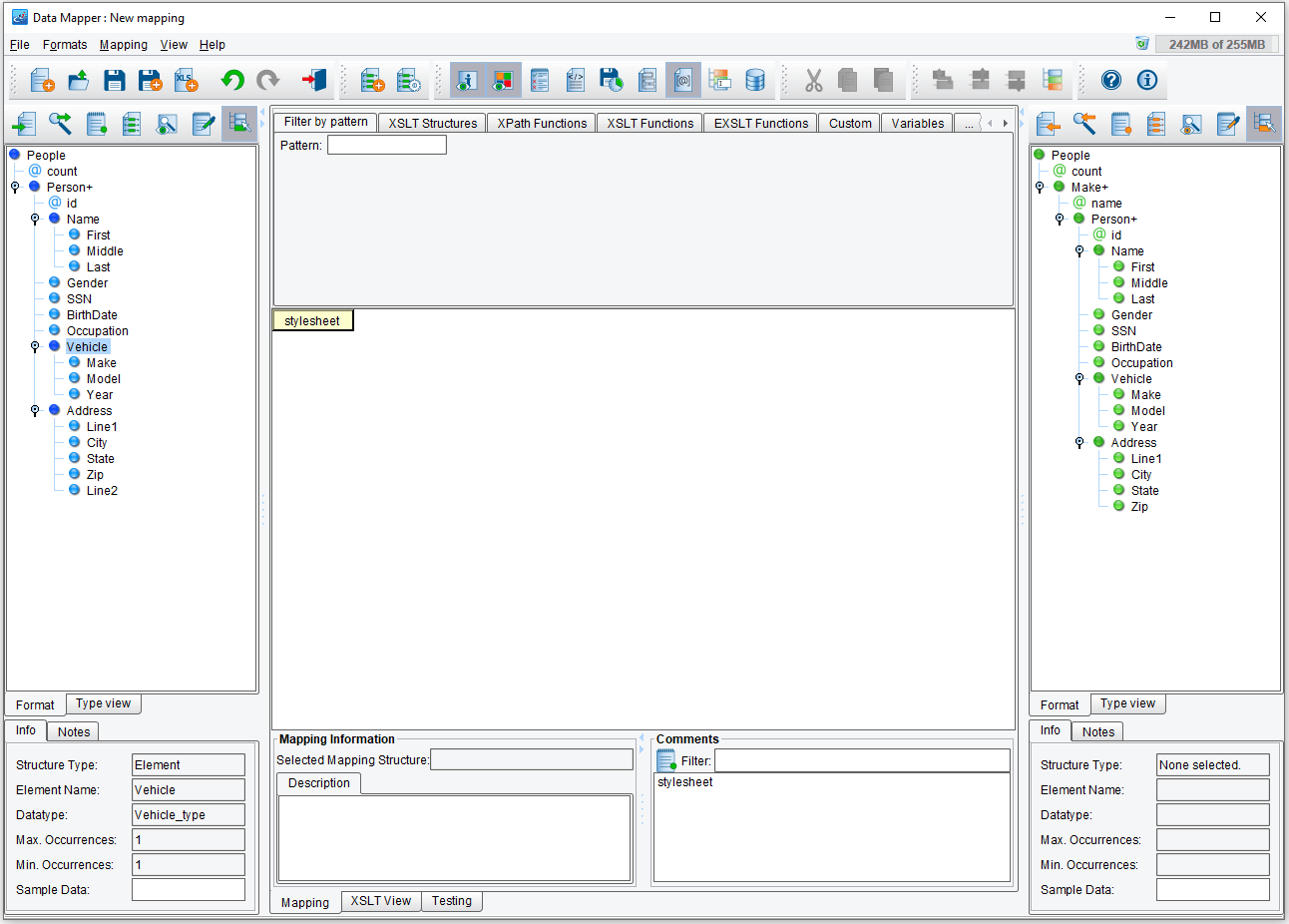
The structure in the Target format is similar to the Source, except that Person elements are grouped under a “Make” element. Each “Make” element represents a Vehicle Make. The goal for this mapping is to group Person elements according to their respective Vehicle Make elements. The intuitive, albeit incorrect, way of doing this would be to iterate over each Person or Make element from the Source and then iterate again for each matching Person. However, this would create duplicate groups, as each such Make might appear multiple times.
Using the “Muenchian Method”
The solution is to use something called the “Muenchian Method,” which makes use of XSLT keys to iterate uniquely over some set of elements. Conceptually, this approach is somewhat complex, though it is too useful to ignore.
The first thing we’ll need to do is to create a key. XSLT keys are structures that are conceptually similar to the Dictionary in .NET languages (such as C#) or the “Map” in Java. A key is a collection of values “keyed” according to some other value. For example, if we were to create a key mapping “Gender” values to “Person” elements, we would have key entries for “Male” and “Female.” Each such key would point or map to a set of Person elements. Passing in “Male” to the key object (via the key function) would return the Person Node set.
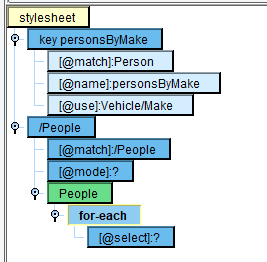
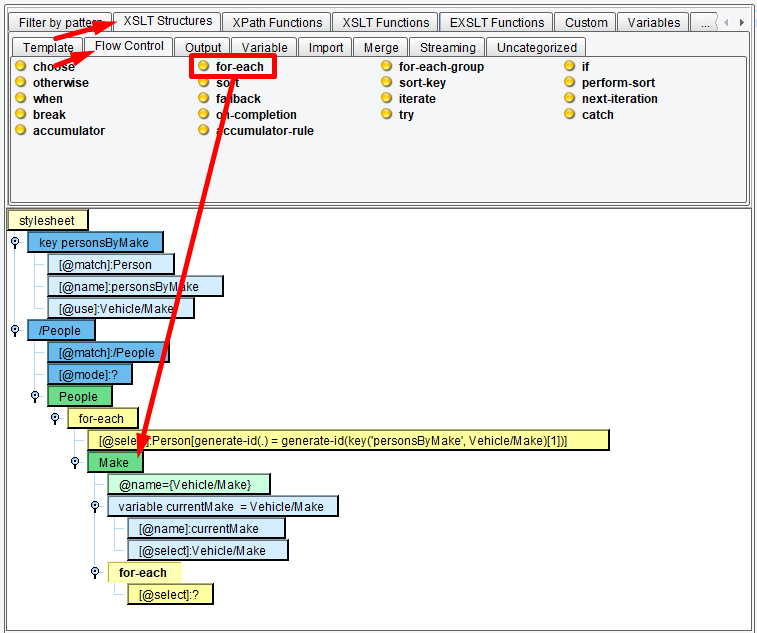
For our case, our key will map the “Make” element to “Person” elements. Click the XSLT Structures tab, the Variable tab and then drag the variable key onto the stylesheet element:
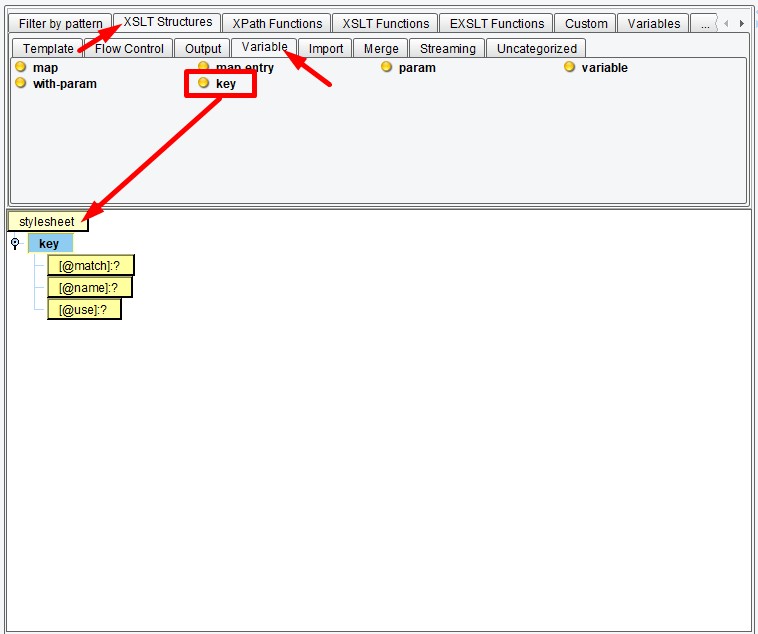
The created structure has match, name, and use attributes:
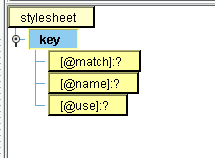
The match attribute is the expression we wish to match against and use as values in our key object. In our case, that will be Person elements. Modify the expression to read:
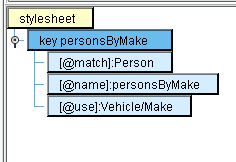
Person
“name” is the name of the key object we’ll use to reference it by later. Modify it to read:
personsByMake
“use” is the expression, relative to the “match” expression (each Person), to use as key entries. Modify it to read:
Vehicle/Make
Your key structure should now look like this:
Mapping Basic Source and Target Root Elements
Next, we’ll wish to map the basic Source and Target root elements:
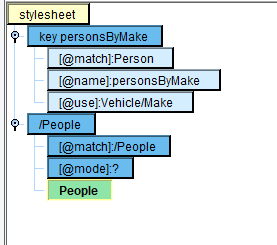
We’ll want to iterate over each Person in our Source, so provide the for-each expression and its initial expression:
Double-click on the select attribute to modify the for-each expression. Change it to read:
Person[generate-id(.) = generate-id(key('personsByMake', Vehicle/Make)[1])]
As expressions go, this one is obviously a bit complicated, so we’ll break it down. We’ve added a predicate to Person which tests if the results of the function “generate-id(.)” match the results of another such function. “generate-id()” returns a unique ID for the node passed as its argument. The XSLT specification provides no information as to the structure of that ID; only that it is unique for the given node in a particular XML document. That means that, within a given transform, values are unique, but should not be used outside of those purposes, as two unrelated Nodes in two disparate documents could share such an ID.
The second part of the expression is the “key” function called against our created key with the current Person’s “Make” as the key. This will return a node set containing each Person node with a matching Make element. We then use the “[1]” value to grab the first such node, guaranteed to be in document order. Finally, we get the ID of this node.
The result of all of this is a predicate that tests to see if a given Person is the first such Person with a given Make. Our for-each, therefore, iterates only once uniquely, for each Make. We’ve effectively managed deduplication as a result.
Mapping and Populating
Next, we can map “Make+” from our Target onto the “for-each”.

Populate its “name” value with the Source “Make”:
{Vehicle/Make}
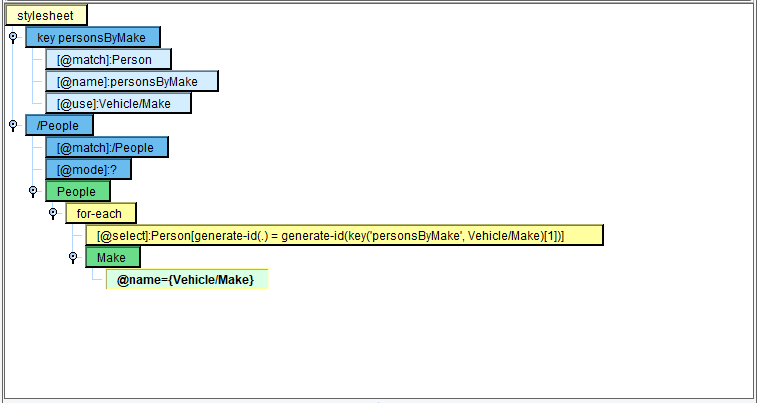
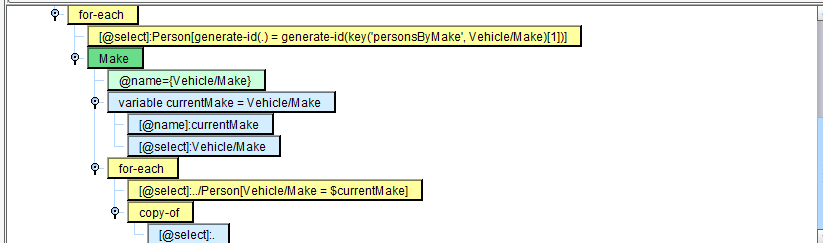
We’ll now create a variable to store the current Make, then iterate over each Person with a matching Make:

Modify the expressions to read: currentMake and Vehicle/Make
Modify the expression to read: ../Person[Vehicle/Make = $currentMake]

We can use the XSLT “copy-of” instruction and the current node as an argument to copy whatever Person we’re iterating over:

Populate @select with a period. Selecting with a period means copying the current node, so in this case the path is at ../Person[Vehicle/Make = $currentMake]
Testing the Mapping
Select the Testing tab…
…and click the Green arrow icon to begin testing.

XSLT and XPath provide numerous other functions, all of which are available in the tool palette at the top of the Data Mapper screen. Click on the View Results button for more convenient checking results. Test the mapping and you should see the following output.
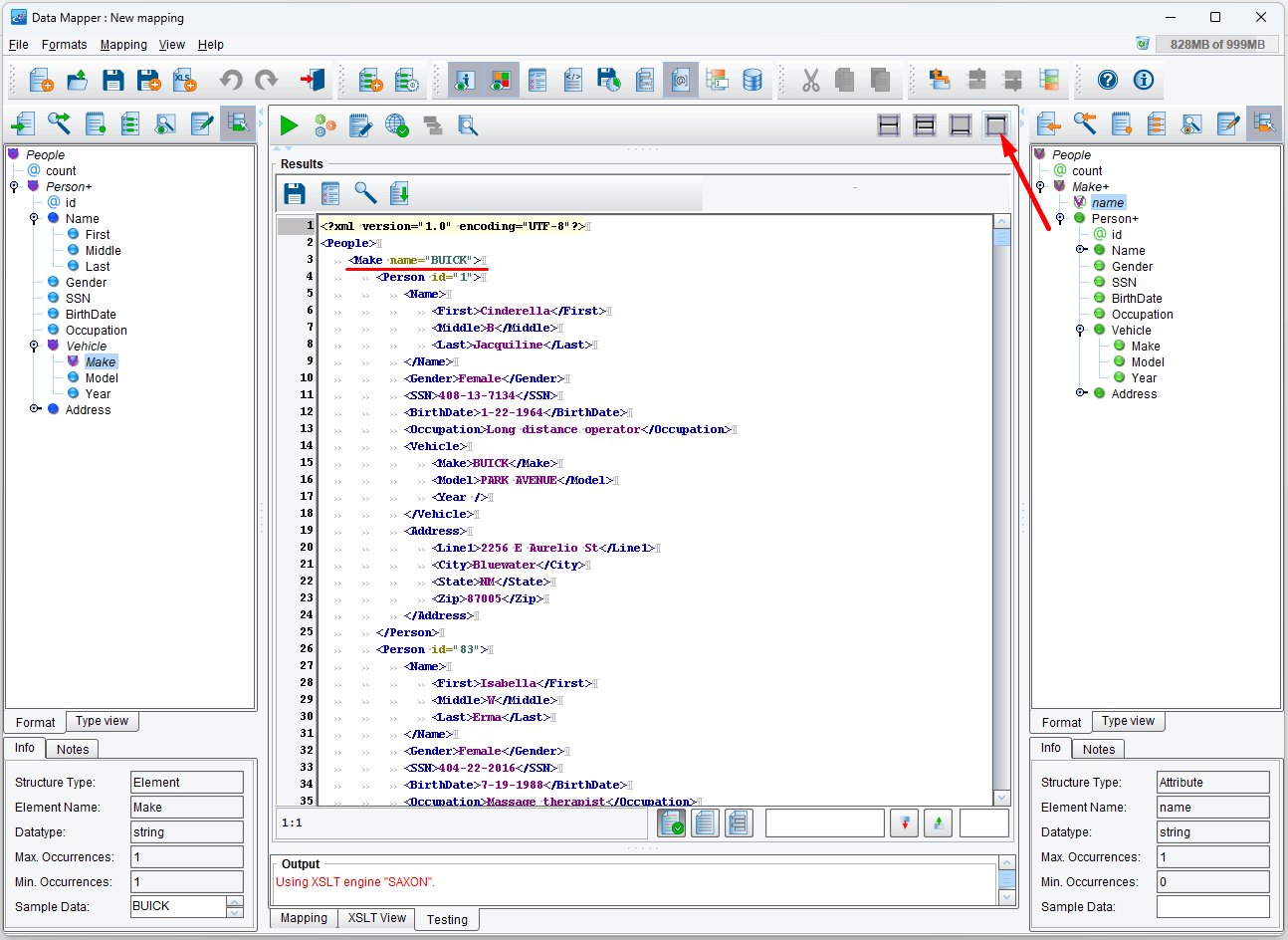
Keys and the Muenchian method can be extraordinarily useful for such circumstances and while the syntax and concepts can be a little difficult to grasp, they are well worth learning.