eiConsole for ACORD – HL7 to ACORD (Demo)

Nowhere is there a higher value to timely, cohesive, and accurate information than in the healthcare industry. In the moment of a medical crisis, the immediate availability of personal medical history can be the difference between life and death. In a time of economic turmoil for healthcare providers, the ability to reduce costs through healthcare data integration can be the difference between institutional survival and bankruptcy. The eiConsole fully supports the HL7 2.X and HL7 version 3 messaging standards. The eiConsole offers an HL7 Transformation Module capable of converting traditional HL7 data segments into a more easily manipulated XML representation. Once converted to XML, the Data Mapper provides drag & drop mapping to and from the HL7 data formats to any other proprietary or standards-based format. In this demonstration, we’ll show you how an HL7 data feed is converted into an ACORD feed.
The first screen you see here is the Route File Management window. It depicts a list of routes together which comprise an interface that is present in the current eiPlatform/eiConsole working directory. We double click the Interface to open it in the Main Route Grid.
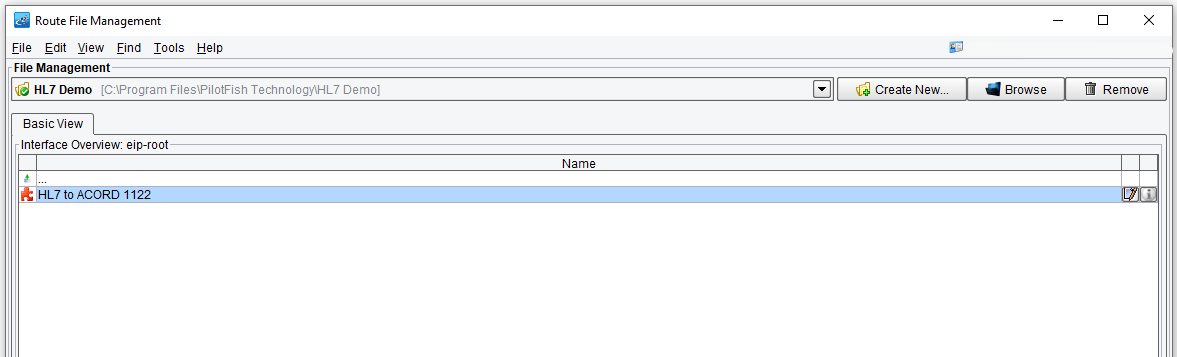
Here we see the flow of data between any defined Source Systems and any defined Targets. The developer’s job when they use this tool is to configure the stages between the Source and Target.

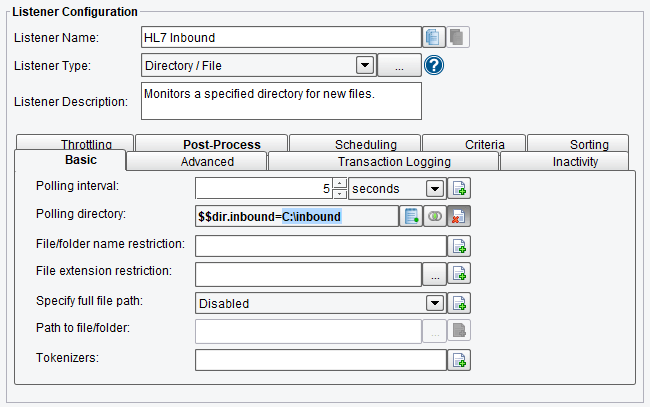
We begin with the Listener that handles the connectivity to the Source System. The eiConsole supports a number of different types of Listener configurations for accepting the HL7 or another type of data. In this case, we’re pulling the data from a directory.
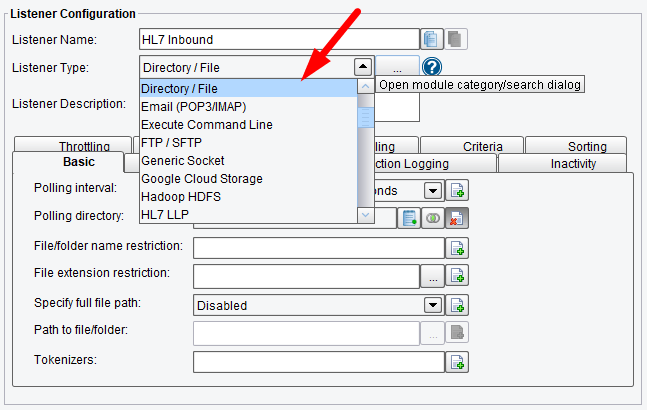
The C:\inbound directory on a local machine.
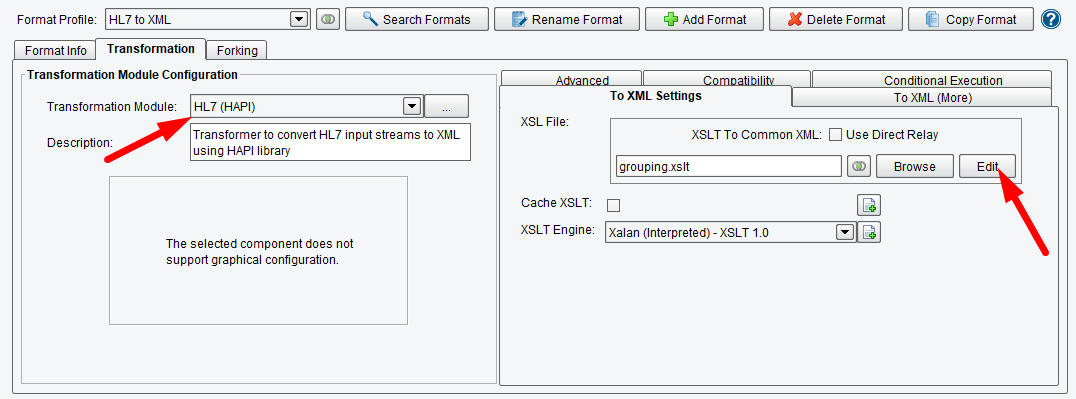
The next stage is the Source Transformation. Each transformation in the eiConsole has two stages. First, a Transformation Module to convert the data to XML, and then an XSLT Configuration that converts the data into a chosen canonical model. Here, we’re accepting HL7 data, parsing it into a relatively flat XML structure using the HL7 Transformer (HAPI) Module, and then imposing a hierarchy on the inbound HL7 with a grouping transformation.
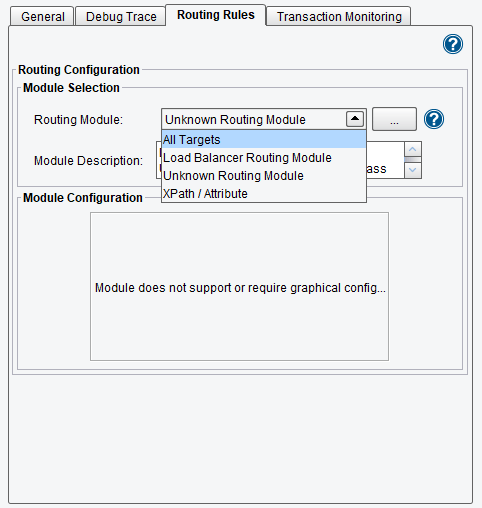
The next step is the Routing stage. Here we can implement Routing Rules that will allow us to select which Target System or Systems to send the data to. In this case, we only have one Target that expects ACORD XML, not HL7, so that will be the Target Transformation that we use. However, if we had multiple different Target Systems we could select between those Targets based on data in our inbound feed. The XPath or Attribute based Routing Module allows us to enact those types of rules.
Once we determine which Target System should be in receipt of the data, we move on to the Target Transform. Here we’re doing the bulk of our data mapping between HL7 and a proprietary format. In this case, the proprietary format is actually another standard, its ACORD.
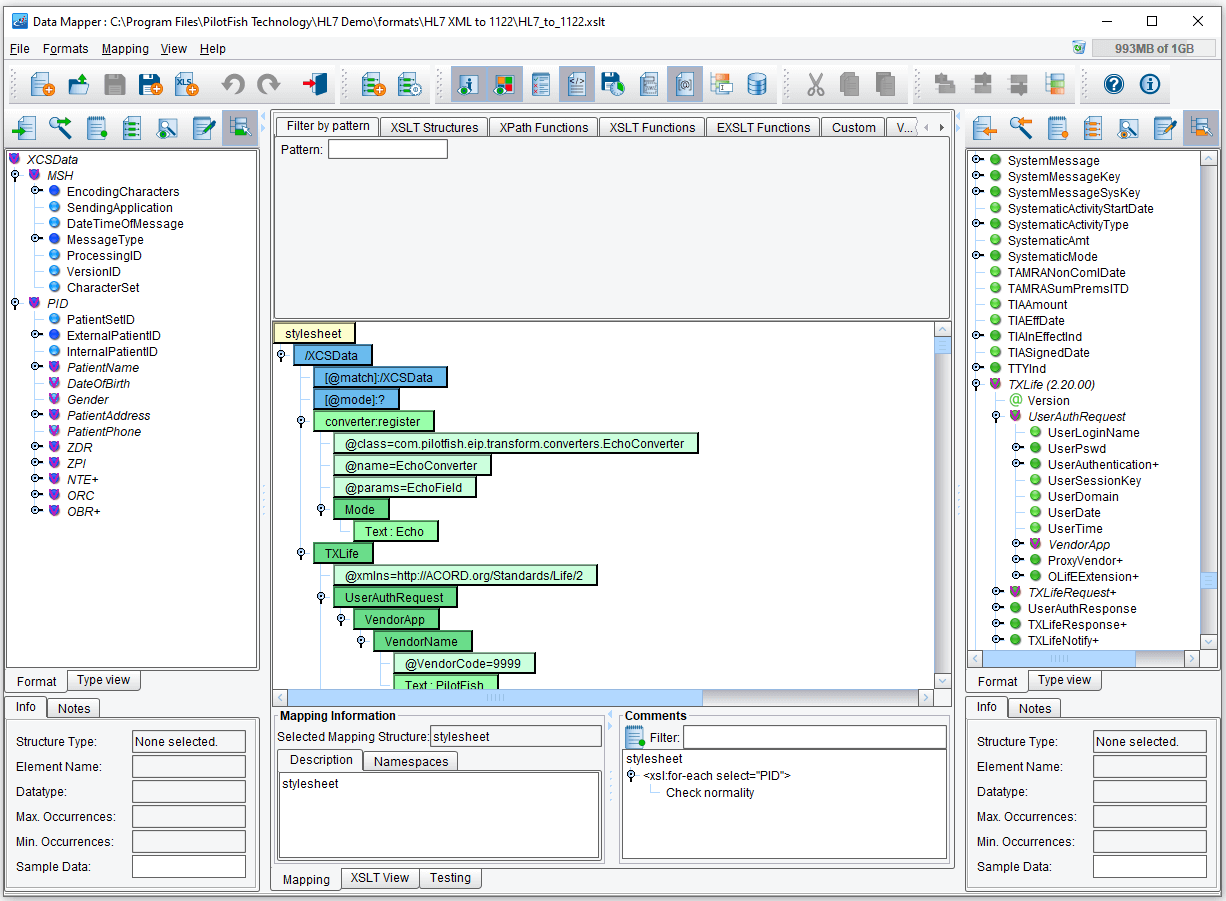
All logical data mapping in the Console takes place in the Data Mapper. Here you see a tree on the left that represents the structure of our Source data and a tree on the right that represents the structure of our Target data.
On the left-hand side, we’ve loaded a sample of our XMLized HL7. You can see here that the root is an XCSData tag. However, we then have nodes that represent HL7 structures and their hierarchy.
When we get down to the leaf nodes we have individual fields or segments within the HL7.
On the right-hand side, we’ve loaded the ACORD TXLife model. In the middle, we see the logical mapping between the two. For instance, here we can see we’re generating a Person and FirstName tag, this is ACORD nomenclature, and we’re populating them with the PatientName/FirstName, PatientName/MiddleName, and PatientName/FamilyName fields from the inbound HL7. Source nodes are in blue, Target nodes are in green.
Mapping between different sets of code values is possible using the Tabular Mapping tool. For instance, here we map between HL7 Source values of F and M for Female and Male and ACORD code values of 2 and 1.
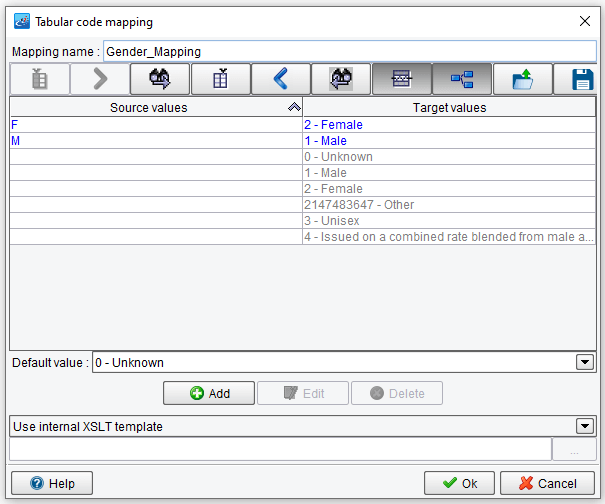

A number of other tools used for common translations of data formats are also available. Here you can see the date of birth being formatted from an HL7 fixed position format into an XML appropriate and ACORD appropriate yyyy-MM-dd format.
All of these mappings are accomplished via drag & drop and result in the generation of W3C standard XSLT.
After the data has been translated into the appropriate Target format, we then move on to the Transport stage. The Transport stage handles the connectivity to our Target System and can batch or real-time, synchronous or asynchronous. There are a number of different Transport Types available to us.
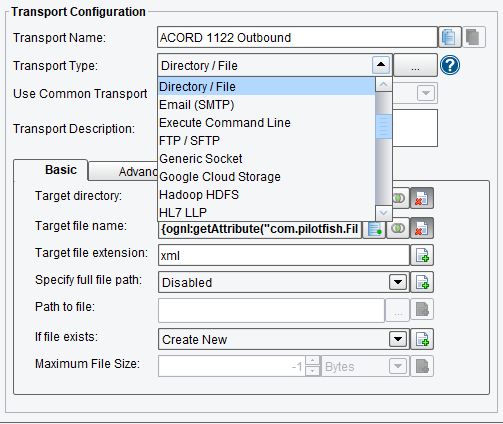
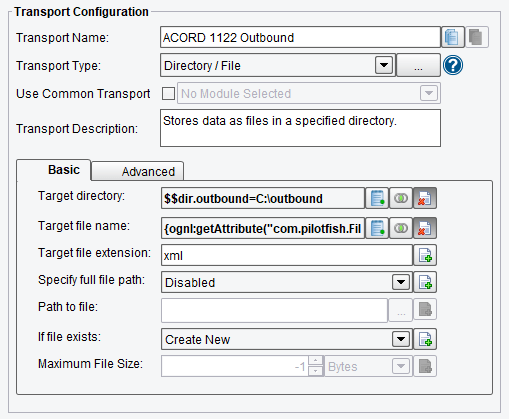
But in this case again we’ve just selected the Directory Transport dropping the result in a file called the same thing as our inbound file name, in a directory called C:\outbound with the new extension of xml.
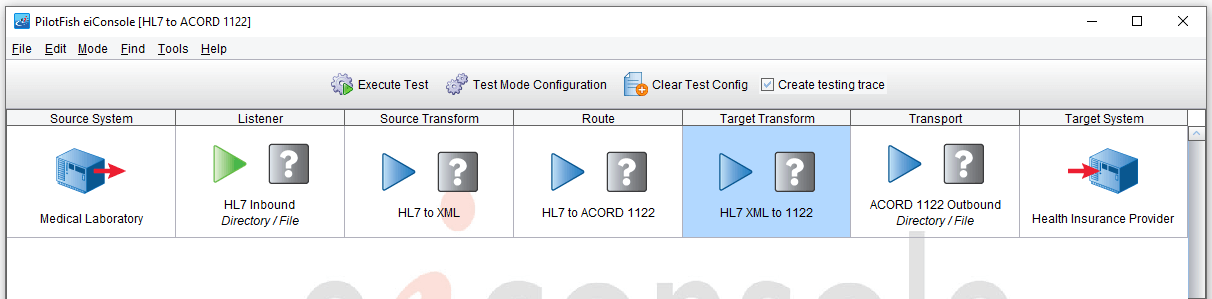
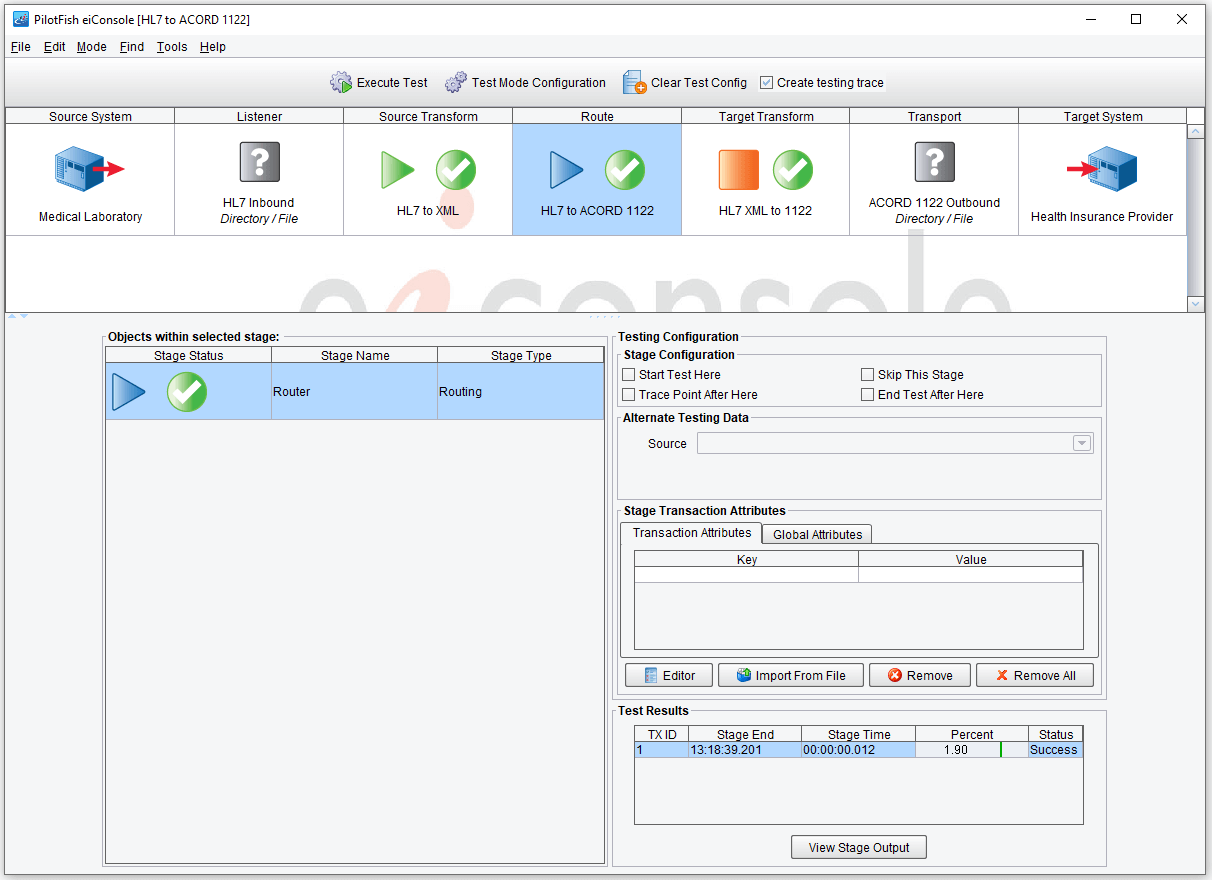
Once an interface has been configured we can switch the eiConsole to Testing Mode. In Testing Mode the icons between the Source System and Target System are no longer there, they’re replaced by these question marks. This allows us to choose where we want to start and end the test.
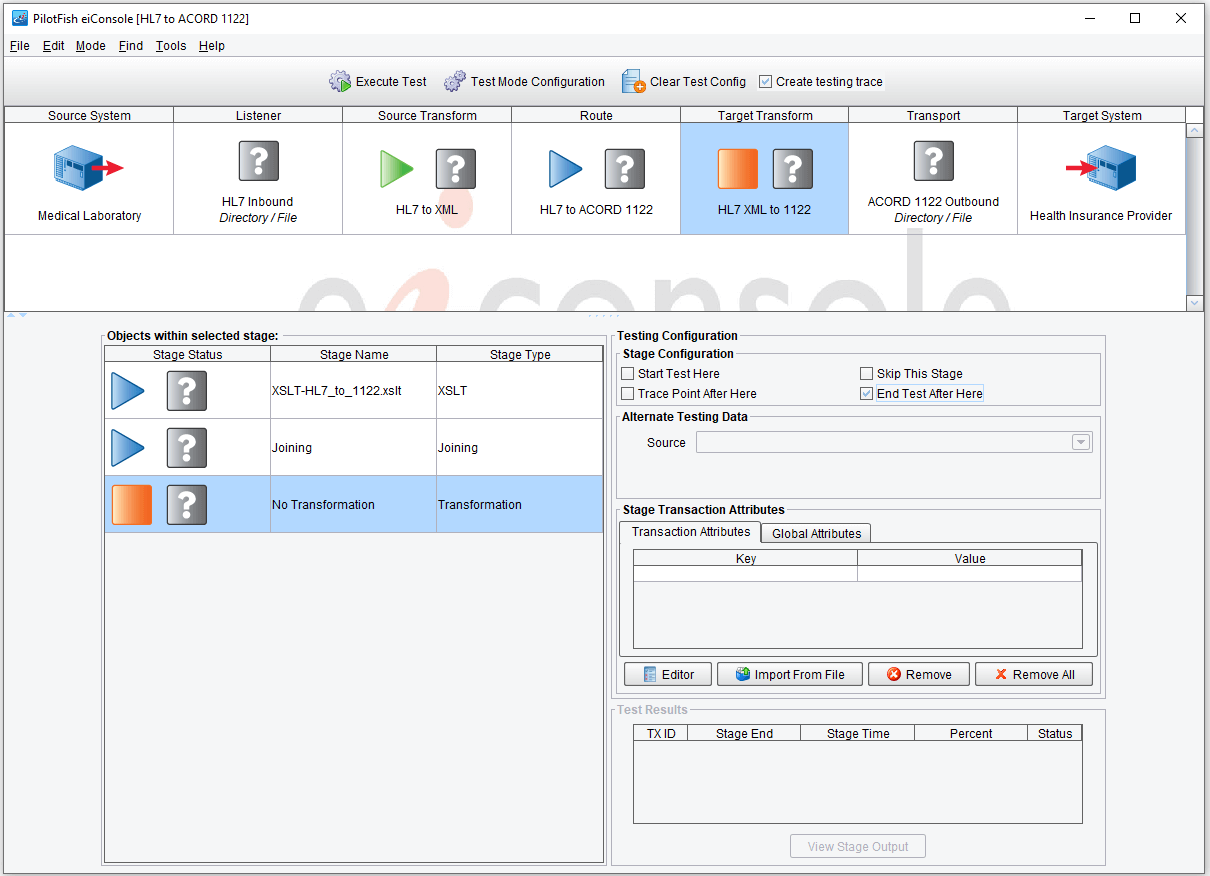
Here we’ll start with our Source Transformation and end with the result of our Target Transform. Once configured a green arrow indicates our starting point, a red square our stopping point, and blue arrows any stages that may be invoked in between.
We’ll click the Execute Test button and we’re asked to provide some sample data. In this case, we’ll grab a sample HL7 file.
Click Open. As each stage completes the question marks turn into checkmarks.
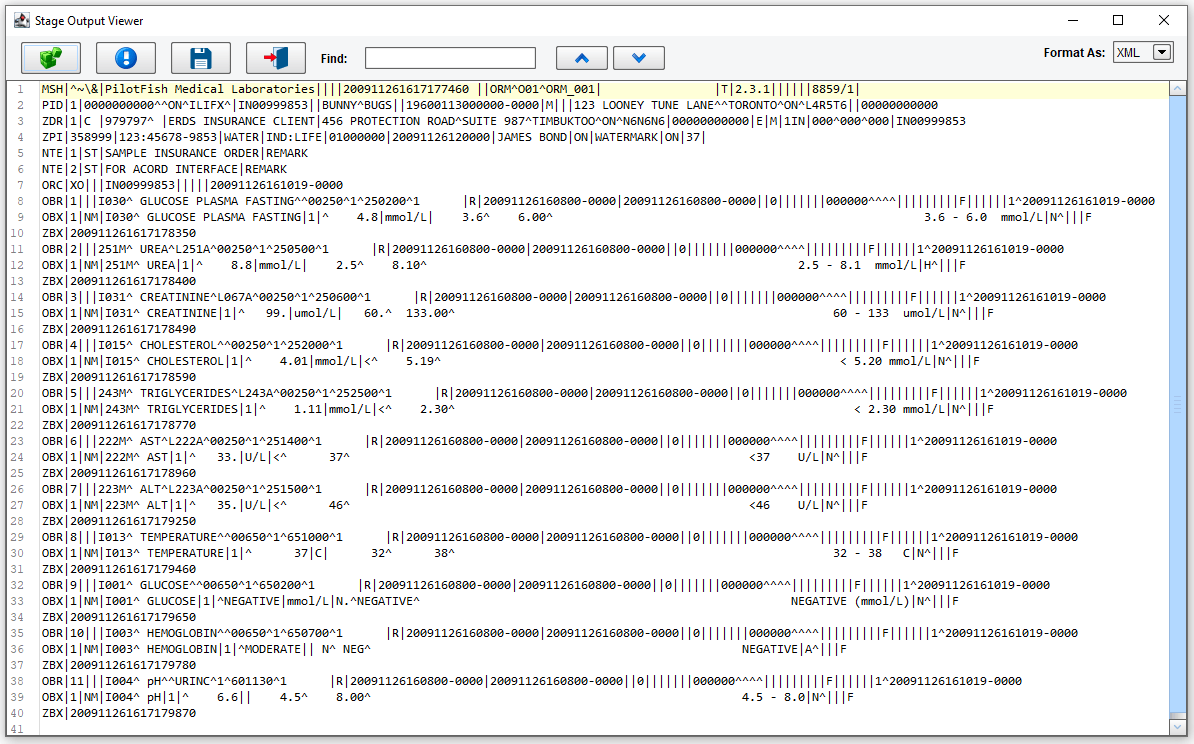
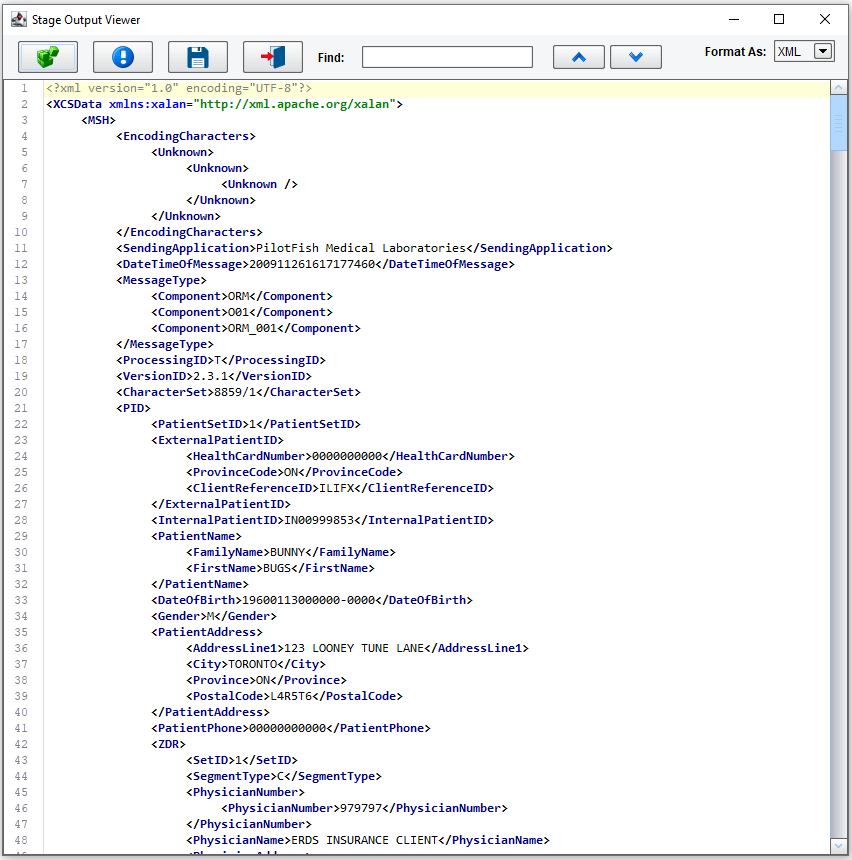
We can take a look at how the data appeared at each point in the process. Starting with our beginning stage we can view the input, familiar HL7 Delimited data.
We can then click the Results of our first transformation stage. You can see here we’ve parsed the HL7 data into an XML representation of that HL7.
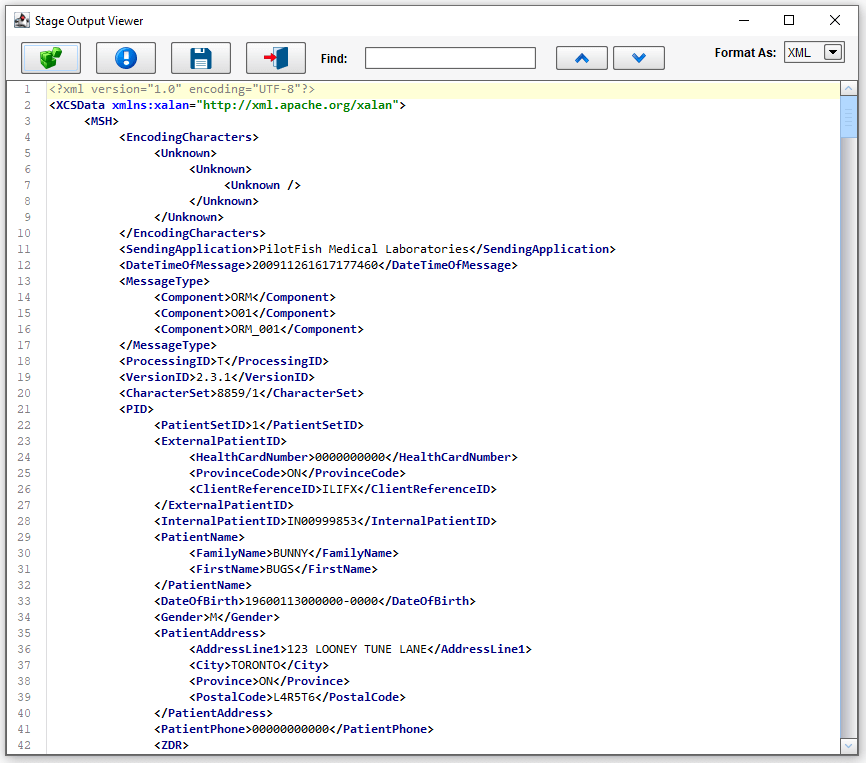
Next, we did some grouping on that inbound data so that we could impose a structure that is more amenable to mapping.
We routed the data along to our one defined Target, which then invoked another XSLT that converted the HL7 data into an ACORD standard TXLife request. In this case, the data being sent were lab results.
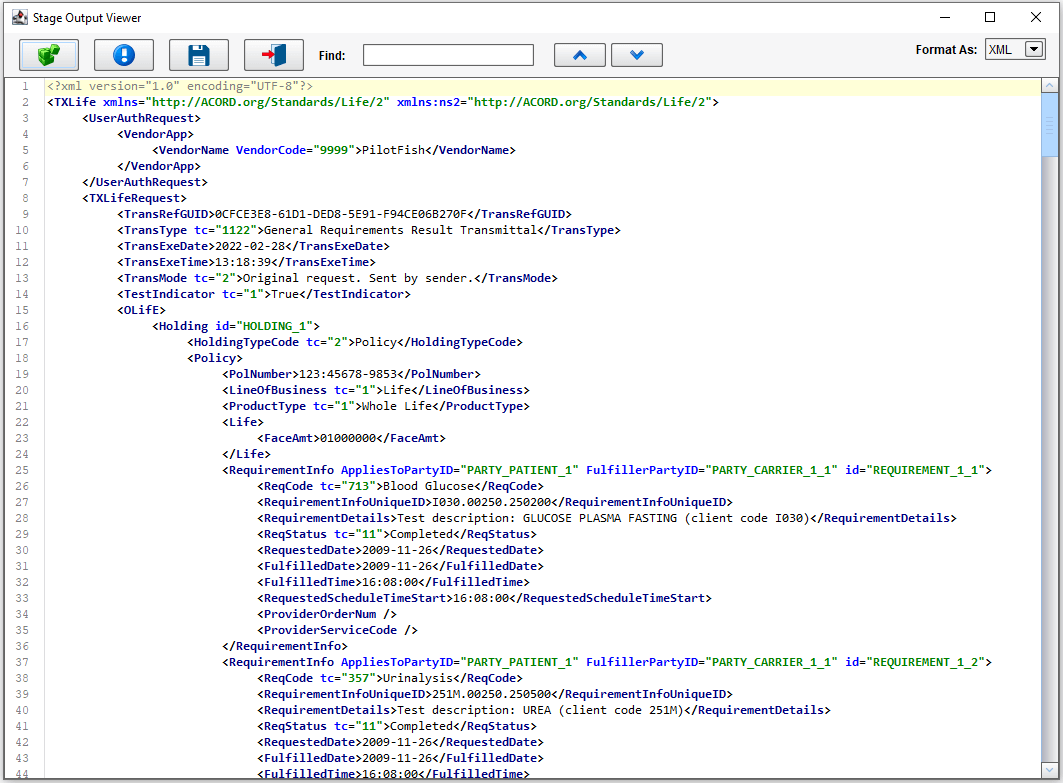
To review, the Main Route Grid was used to configure the flow of data between the Source System and the Target. The Listener handled the connectivity. The Source Transformation, the parsing of data into an XML representation of HL7. The Routing stage passed the data along to our single defined Target. The Target Transform further translated the data to ACORD, and the Transport handled our connectivity to the Target System.
It’s as simple as that, point-click, drag & drop your way to HL7 integration with any other system.