OpenAI Processor
The OpenAI Processor enables interaction with the OpenAI Completion API, facilitating integration with AI capabilities. This allows the sending of messages and return responses.
An example use-case would be dealing with unstructured data, which can pull elements from data provided to its prompt with a task to parse those elements into a CSV file. With the data now in a structured CSV format, other PilotFish modules can be subsequently leveraged to transform, extract and map the data to other systems.
A prerequisite for this Processor is the need for an account and API key. This can be set up by accessing the OpenAI Developer Platform.
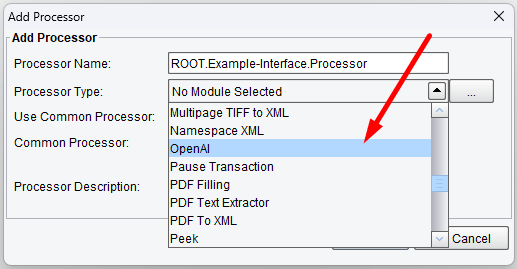
Processor (Adapter) Configuration Drop-Down List
Select OpenAI from the drop-down processor list and click on Add.
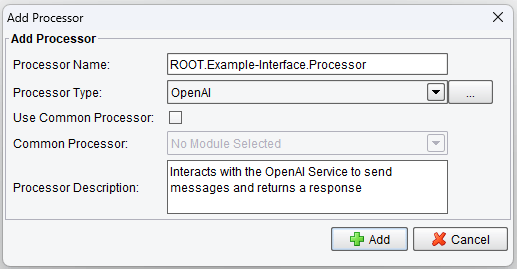
Click on Add
Basic OpenAI Processor Configuration Options
Before you begin, ensure you’re on the Basic tab where you’ll configure the core settings for the OpenAI Processor. These settings are crucial for establishing communication between your application and the OpenAI Service. Here’s what each option entails:
- Request Identifier – unique Identifier representing the entity that initiated the API request
- Prompt – text input used to get a response back from OpenAI
- Model – this field determines which OpenAI model your prompt will be processed with, the default is gpt-3.5-turbo
- API Key – API Key used to authenticate your requests with the OpenAI service
- Max Tokens – the maximum length of the response, measured in tokens, where one token is approximately 4 characters of text
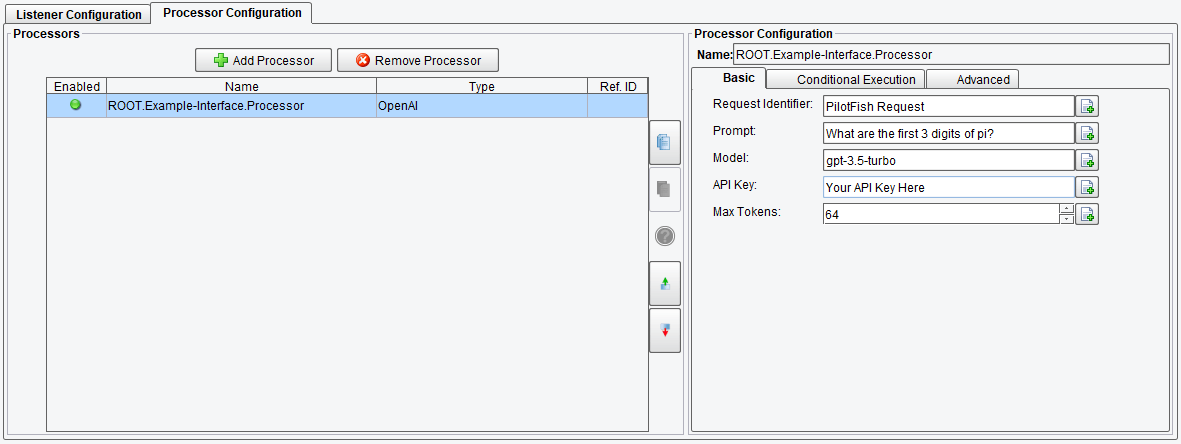
OpenAI Processor Basic Configuration Options
Request Identifier
The request identifier serves as a unique audit trail for requests made with your API Key. This can be left as the default value, but we recommend customizing it to reflect a unique aspect of your process, such as the machine or process name, for easier tracking.
Prompt
The prompt is the text that will be parsed and used during the OpenAI Text Completion. This is where you ask your questions or ask OpenAI to do something with the data inside the prompt.
Model
Currently, the default is gpt-3.5-turbo. This is a freeform text field as there are potentially unlimited different models that could be accessible for use. To get a list of available models reference OpenAI’s text generation model documentation.
API Key
This key is how OpenAI knows who is performing requests. You can generate a key for your OpenAI account here.
Max Tokens
The max tokens setting limits the number of tokens that can potentially be spent for the response. This does not mean that it will spend that amount each time. One thing to note is that if a response is longer than the number of tokens (about 4 characters of text per 1 token) it will be cut off at max tokens.
Conditional Execution OpenAI Processor Configuration Options
On the Conditional Execution tab, you can set additional Processor execution conditions. The transaction data dependent condition may be specified here as an enhanced expression. If this expression returns anything other than TRUE (ignore case) – this processor will be skipped. No additional configuration for this Processor is required.
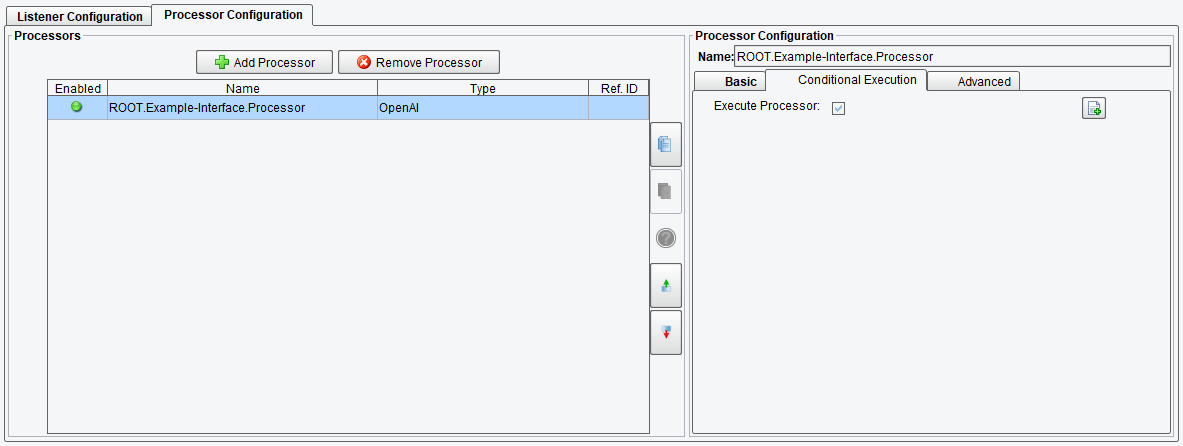
OpenAI Processor Conditional Execution Configuration Options
Advanced OpenAI Processor Configuration Options
There is an additional setting under the Advanced tab which dictates the output Format of the response. By default, the output is in XML format, facilitating seamless integration with core PilotFish tools without requiring additional data transformation. Since OpenAI’s API natively communicates through JSON, an option is provided to retain JSON formatting if preferred.
- Output Result in JSON Format – outputs the response from OpenAl’s API in JSON instead of XML
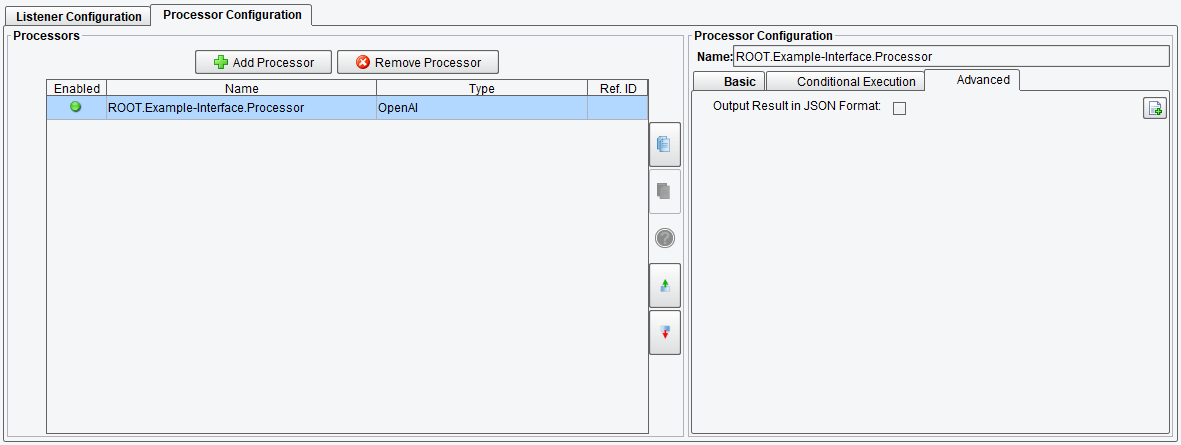
OpenAI Processor Advanced Configuration Options
Here is an example of a result in XML format:
<?xml version="1.0" encoding="UTF-8"?>
<chatCompletionResponse>
<usage>
<completion_tokens>17</completion_tokens>
<prompt_tokens>17</prompt_tokens>
<total_tokens>34</total_tokens>
</usage>
<choices>
<finish_reason>stop</finish_reason>
<index>0</index>
<message>
<content>The first three digits of pi are 3, 1, and 4.</content>
<role>assistant</role>
</message>
</choices>
<created>1708108636</created>
<id>chatcmpl-7zxTFoHQEhNajjp91nJKJXzIvT3n1</id>
<model>gpt-3.5-turbo-0613</model>
<object>chat.completion</object>
</chatCompletionResponse>
Here is an example of result in JSON format:
{
"created": 1708108864,
"usage": {
"completion_tokens": 17,
"prompt_tokens": 17,
"total_tokens": 34
},
"model": "gpt-3.5-turbo-0613",
"id": "chatcmpl-1zxTuQR2QtJByZ5L3g1h3dnBrmsTR",
"choices": [{
"finish_reason": "stop",
"index": 0,
"message": {
"role": "assistant",
"tool_calls": null,
"content": "The first three digits of pi are 3, 1, and 4."
},
"logprobs": null
}],
"system_fingerprint": null,
"object": "chat.completion"
}